
AI在工程应用中的实践:从发展现状到工程应用与未来趋势
Published:

人工智能技术在工程领域的应用正在从理论研究走向实际落地,从单一工具走向系统化工作流,从通用能力走向专业领域深度集成。随着大语言模型(Large Language Model, LLM)技术的快速发展,AI已经从”纸上谈兵”走向”实际行动”,通过Function Calling等技术实现了与外部工具的深度集成,使得AI能够真正参与到工程实践的各个环节中。本文系统梳理AI技术的发展现状、能力边界、工程应用方式、综合撰稿与编程实践、进阶技术路线以及资源整合策略,为工程技术人员提供从理论到实践的完整指南。
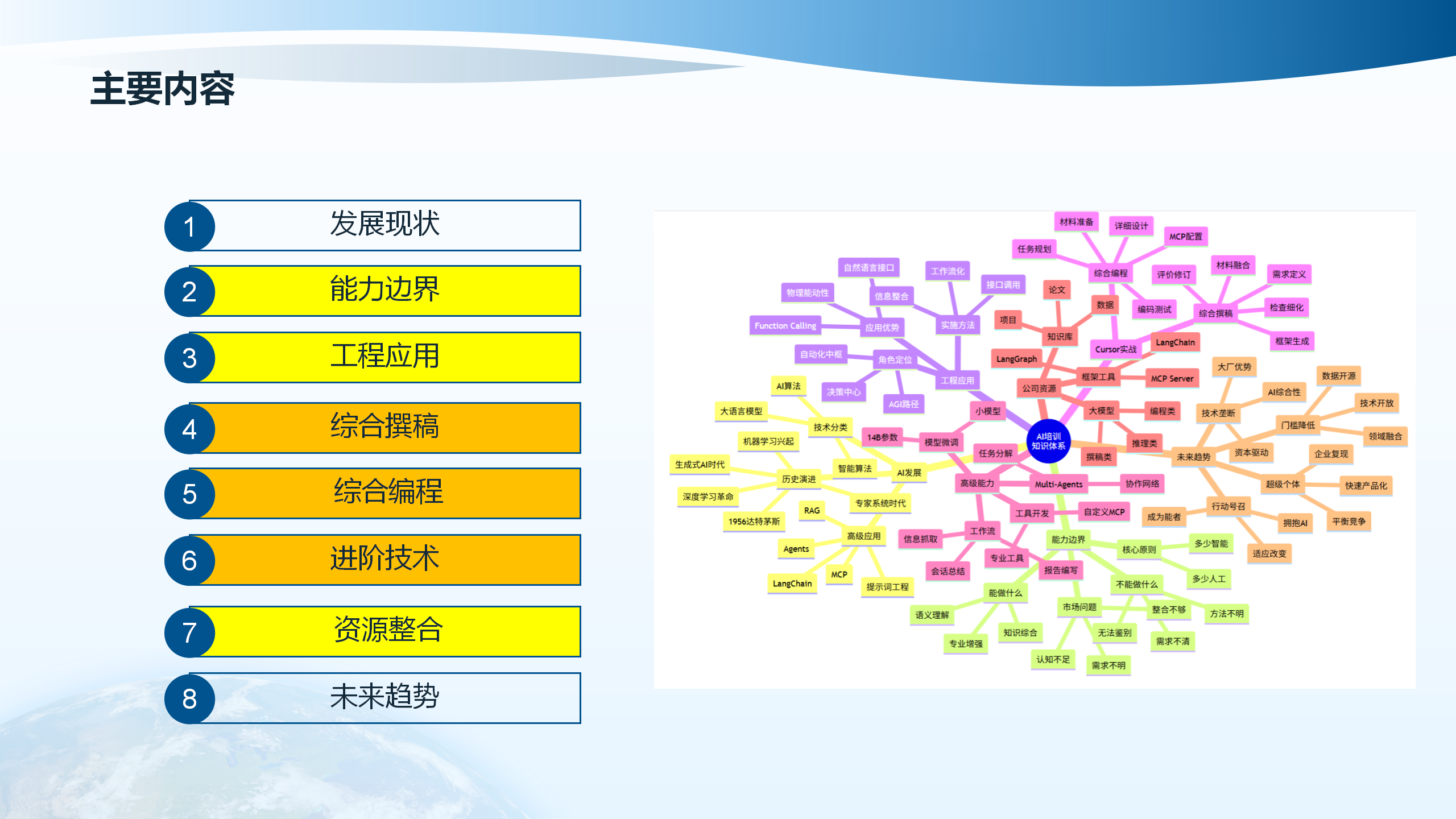
一、发展现状:AI技术发展历史与技术体系
1.1 AI技术发展历史概述
人工智能技术的发展经历了从符号主义到连接主义,从专家系统到深度学习的演进过程。20世纪50年代,人工智能概念正式提出,随后经历了多次发展高潮与低谷。进入21世纪后,随着计算能力的提升和大规模数据集的积累,深度学习技术取得了突破性进展。2012年,AlexNet在ImageNet竞赛中的成功标志着深度学习时代的到来。2017年,Transformer架构的提出为自然语言处理领域带来了革命性变化。2020年以来,GPT系列、BERT系列等大语言模型的涌现,使得AI技术在理解和生成自然语言方面达到了接近人类的水平。
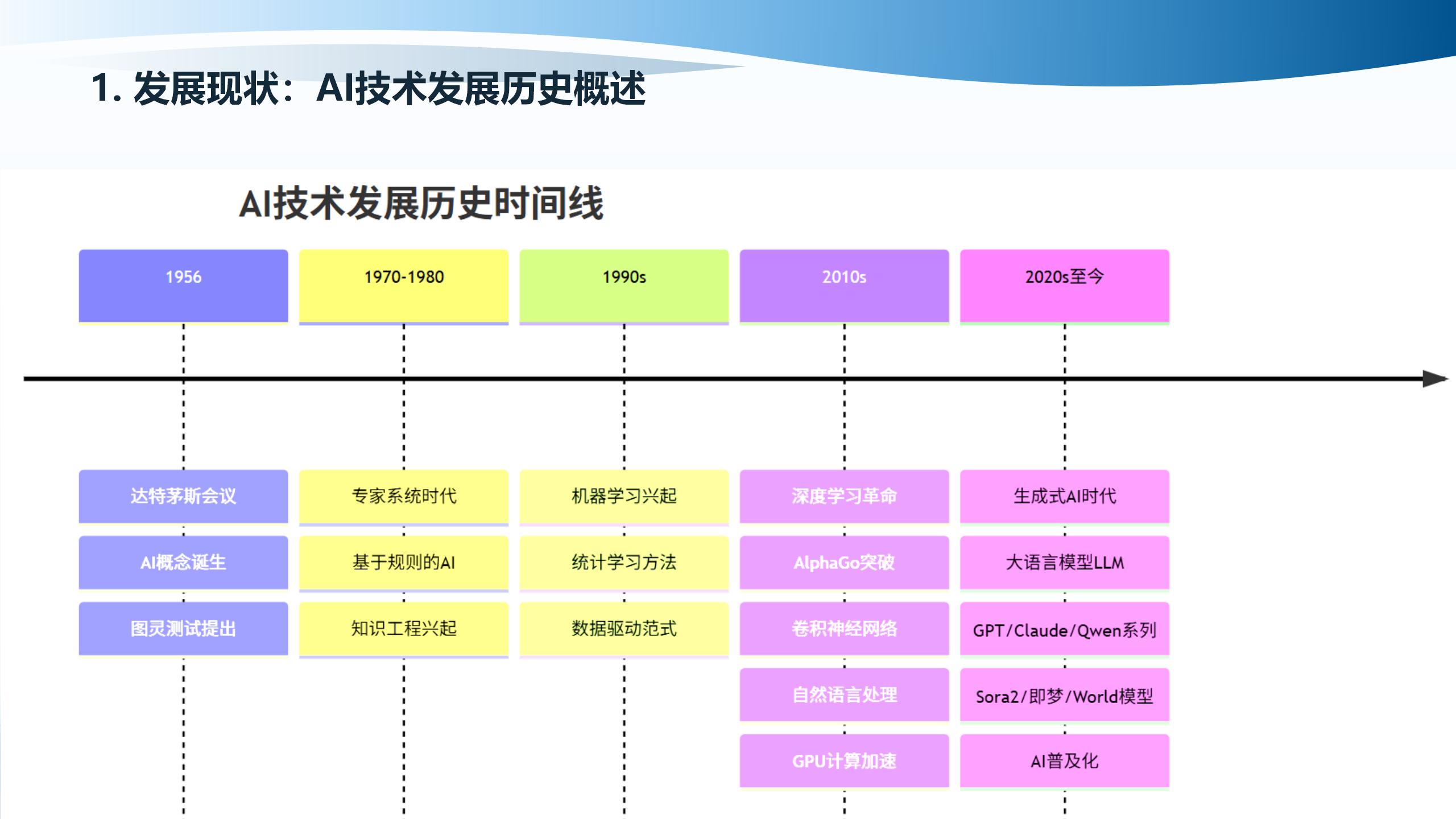
1.2 基础概念分类
AI技术的基础概念可以从多个维度进行分类。从算法类型来看,主要包括监督学习、无监督学习和强化学习。监督学习通过标注数据进行训练,适用于分类和回归任务;无监督学习从无标注数据中发现模式,适用于聚类和降维;强化学习通过与环境交互获得奖励信号,适用于决策和控制任务。
从模型架构来看,主要包括传统机器学习算法和深度学习模型。传统机器学习算法如支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest)等,具有准确、可优化的特点,适用于中小规模数据集。深度学习模型如卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)、Transformer等,能够从大规模数据中学习复杂模式,适用于图像识别、自然语言处理等任务。
大语言模型(Large Language Model, LLM)是基于Transformer架构的大规模预训练模型,通过在海量文本数据上进行预训练,学习语言的统计规律和语义表示。这些模型能够理解和生成自然语言,在文本生成、问答、翻译等任务中表现出色。
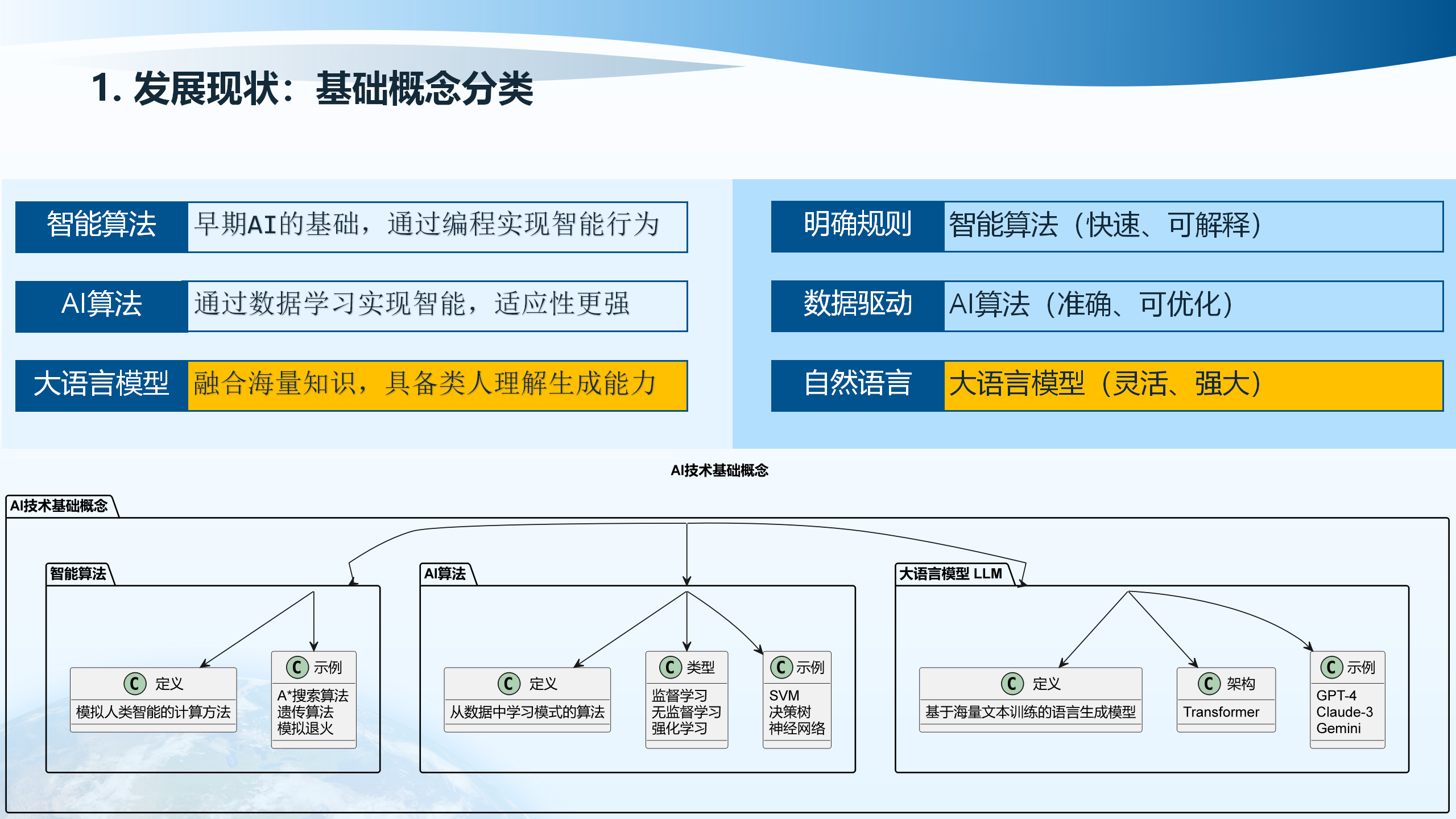
1.3 高级应用技术
随着AI技术的发展,一系列高级应用技术应运而生,这些技术使得AI能够更好地服务于工程实践。
LangGraph是一个用于构建AI链式应用和工作流的框架。它提供了图式工作流编排能力,支持复杂多轮推理,能够将多个AI模型和工具串联起来,形成完整的处理流程。LangGraph支持条件分支、循环控制、状态管理等高级特性,使得开发者能够构建复杂的AI应用系统。
Function Calling(函数调用) 是传统业务逻辑借LLM实现自然语言接口的关键技术。通过Function Calling,LLM可以将用户的自然语言请求转换为具体的函数调用,从而实现对数据库、API、文件系统等外部资源的访问。这使得LLM从纯粹的文本生成工具转变为能够执行实际操作的智能代理。
提示词工程(Prompt Engineering) 是优化输入以提升输出质量的重要技术。通过精心设计提示词,可以引导LLM生成更准确、更符合需求的输出。提示词工程包括角色设定、任务描述、输出格式要求、示例演示等多个方面,是提升AI应用效果的关键手段。
RAG(Retrieval-Augmented Generation,检索增强生成) 技术通过结合外部知识来避免幻觉问题。RAG系统首先从知识库中检索相关信息,然后将检索到的信息作为上下文输入到LLM中,从而生成基于事实的准确回答。RAG技术特别适用于需要专业知识支撑的应用场景。
AI Agents(AI智能代理) 是能够自主执行任务的AI系统。Agent通过感知环境、制定计划、执行行动、评估结果等步骤,完成复杂任务。Agent可以调用外部工具、访问数据库、执行代码等,是实现AI工程应用的重要形式。
二、能力边界:AI能做什么与不能做什么
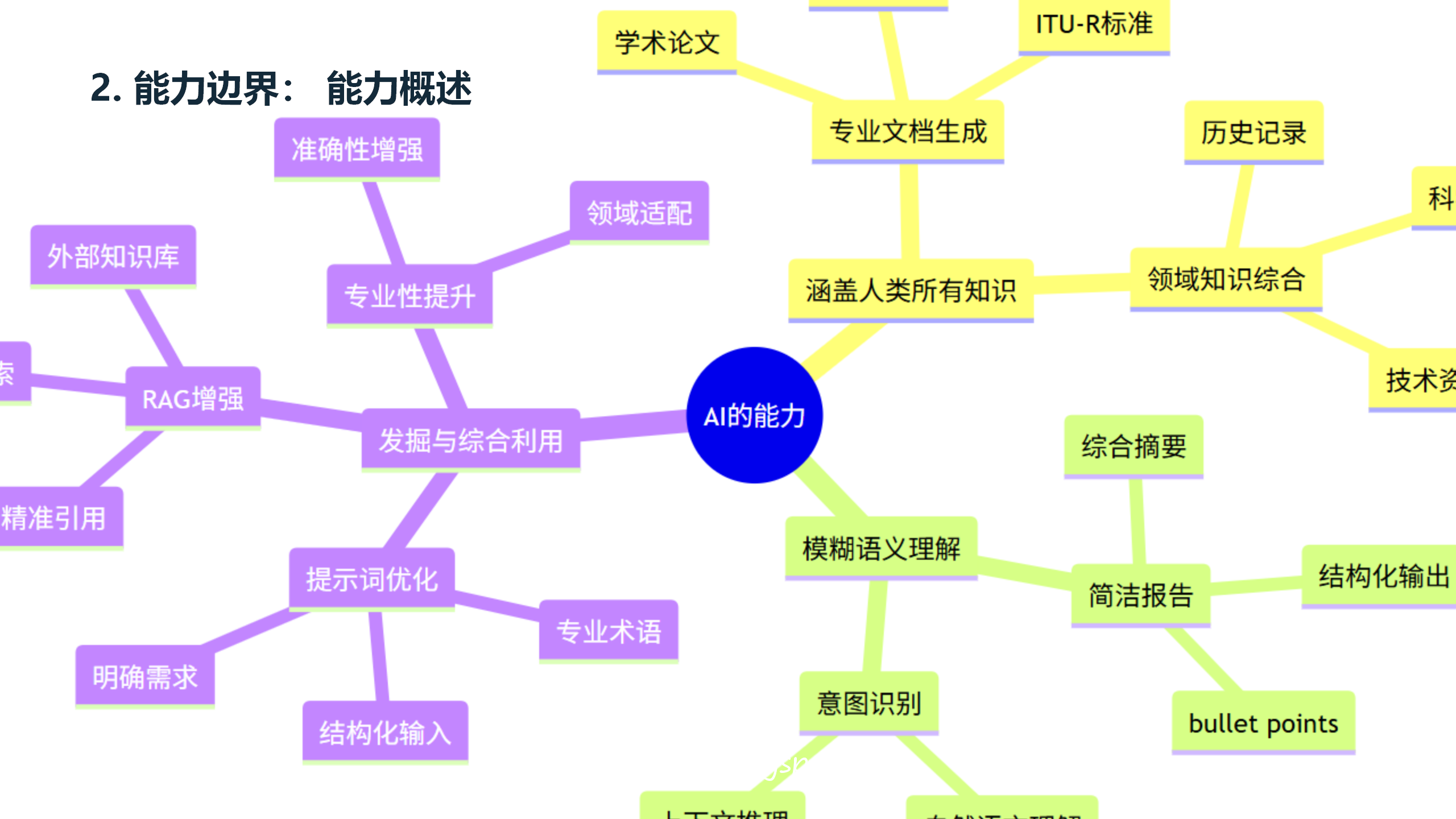
2.1 能力概述
AI技术在工程应用中具有显著优势,主要体现在以下几个方面:首先,AI具有强大的知识整合能力,能够整合人类历史上积累的大量知识,实现跨领域知识融合,快速检索和应用相关信息。其次,AI具有快速原型能力,能够大幅缩短从想法到实现的周期,提升从方案到文档的效率,提高从需求到代码的自动化程度。第三,AI具有应用落地能力,能够将抽象概念转化为具体实现,将专业知识转化为可执行方案,将业务需求转化为技术方案。
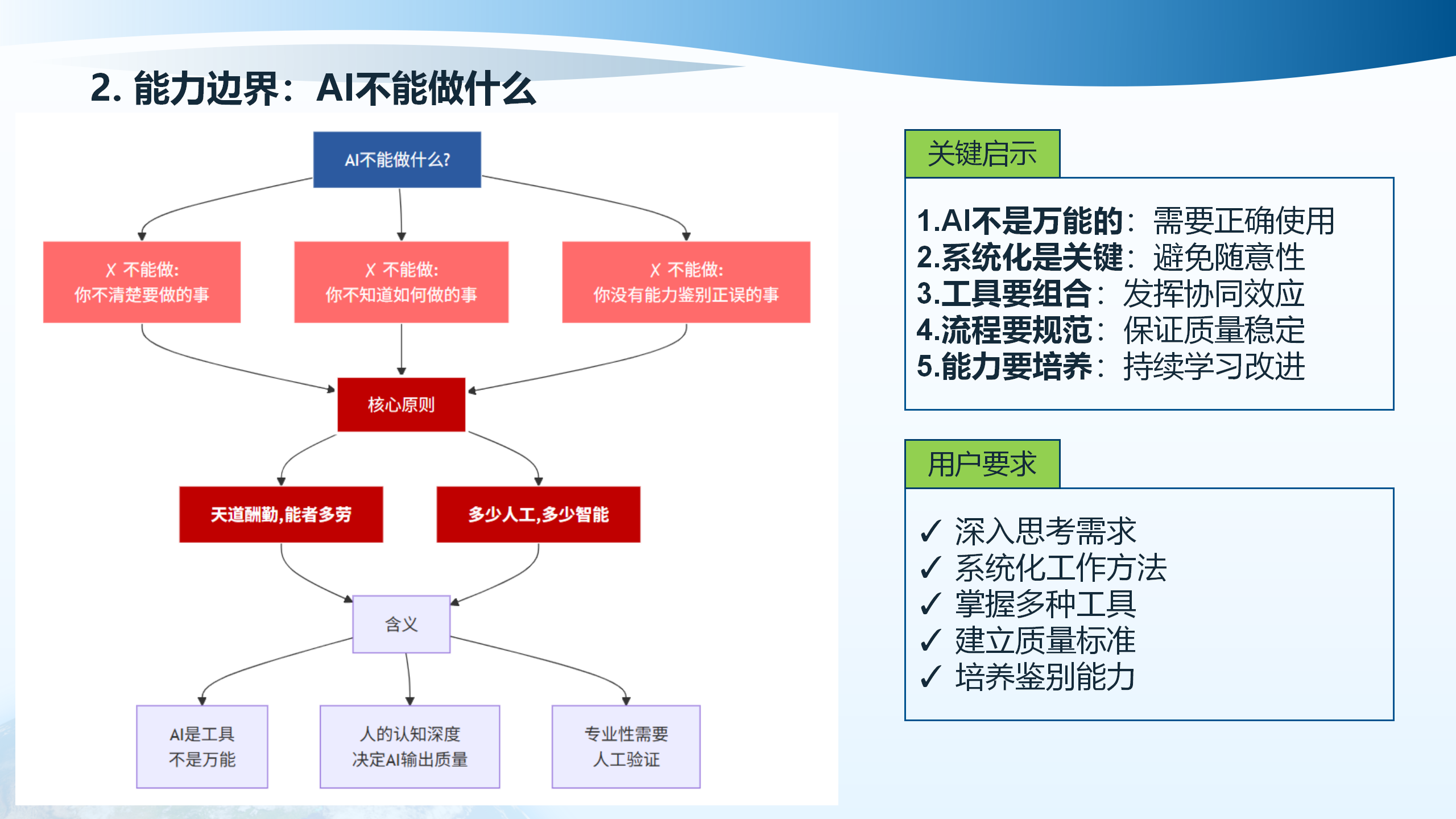
然而,AI的能力边界也清晰可见。AI不是万能的,需要正确使用。系统化是关键,需要避免随意性。流程要规范,需要保证质量稳定。能力要培养,需要持续学习改进。AI不能做用户没有能力鉴别正误的事情,不能替代深入思考需求,不能替代系统化工作方法,不能替代掌握多种工具,不能替代建立质量标准,不能替代培养鉴别能力。
2.2 市场问题与挑战:不熟悉领域
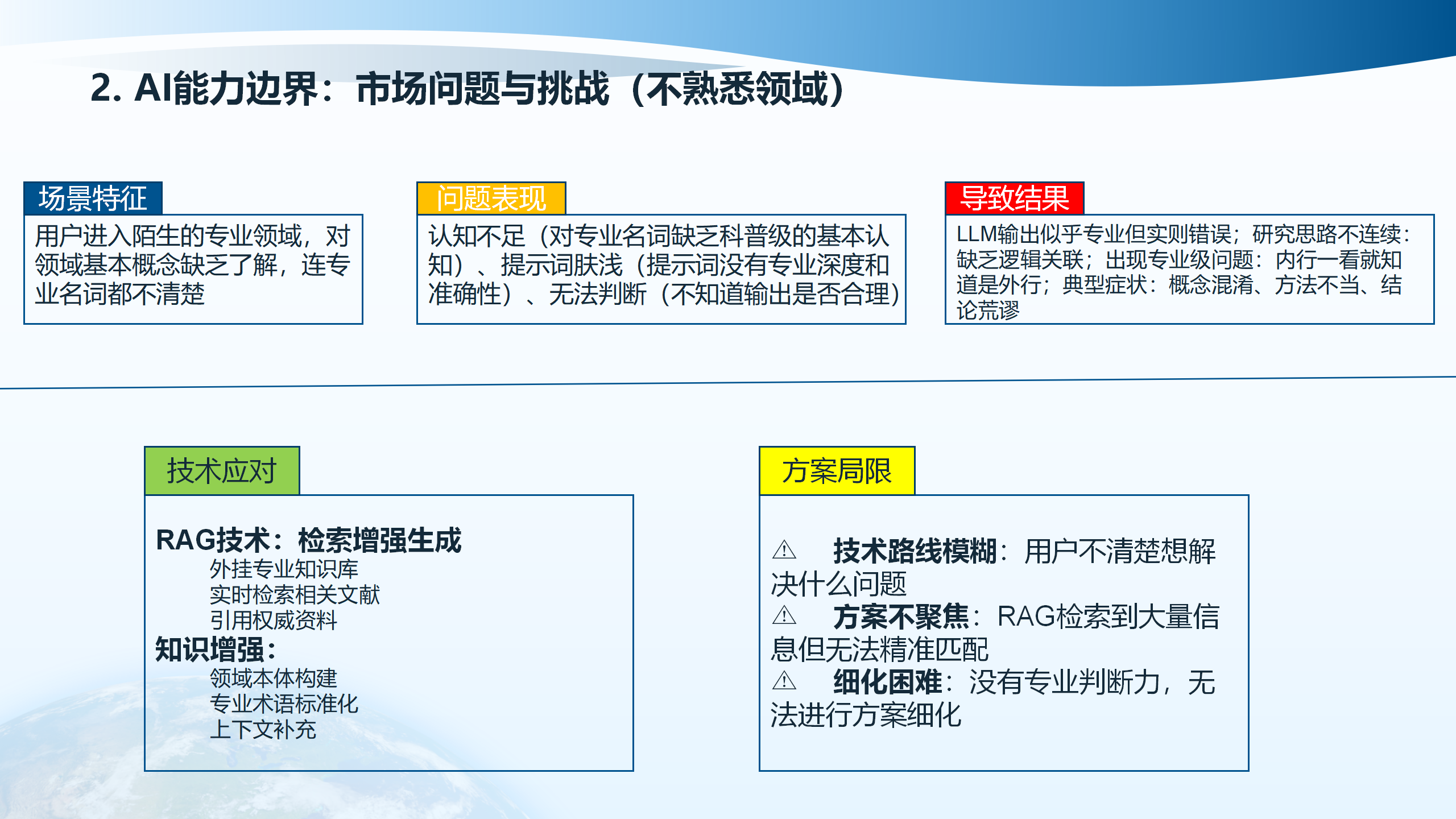
当用户进入陌生的专业领域时,往往面临认知不足的问题。用户对专业名词缺乏科普级的基本认知,提示词肤浅,没有专业深度和准确性,无法判断输出是否合理。这种情况下,LLM的输出似乎专业但实则错误,研究思路不连续,用户不清楚想解决什么问题,方案不聚焦,RAG检索到大量信息但用户没有专业判断力,无法进行方案细化。
针对这些问题,RAG技术提供了检索增强生成的解决方案。通过实时检索相关文献,引用权威资料,构建领域本体,可以帮助用户获取准确的专业信息。然而,RAG技术本身也存在局限性,如果用户不清楚想解决什么问题,RAG检索到的大量信息反而会造成信息过载。
2.3 市场问题与挑战:熟悉领域
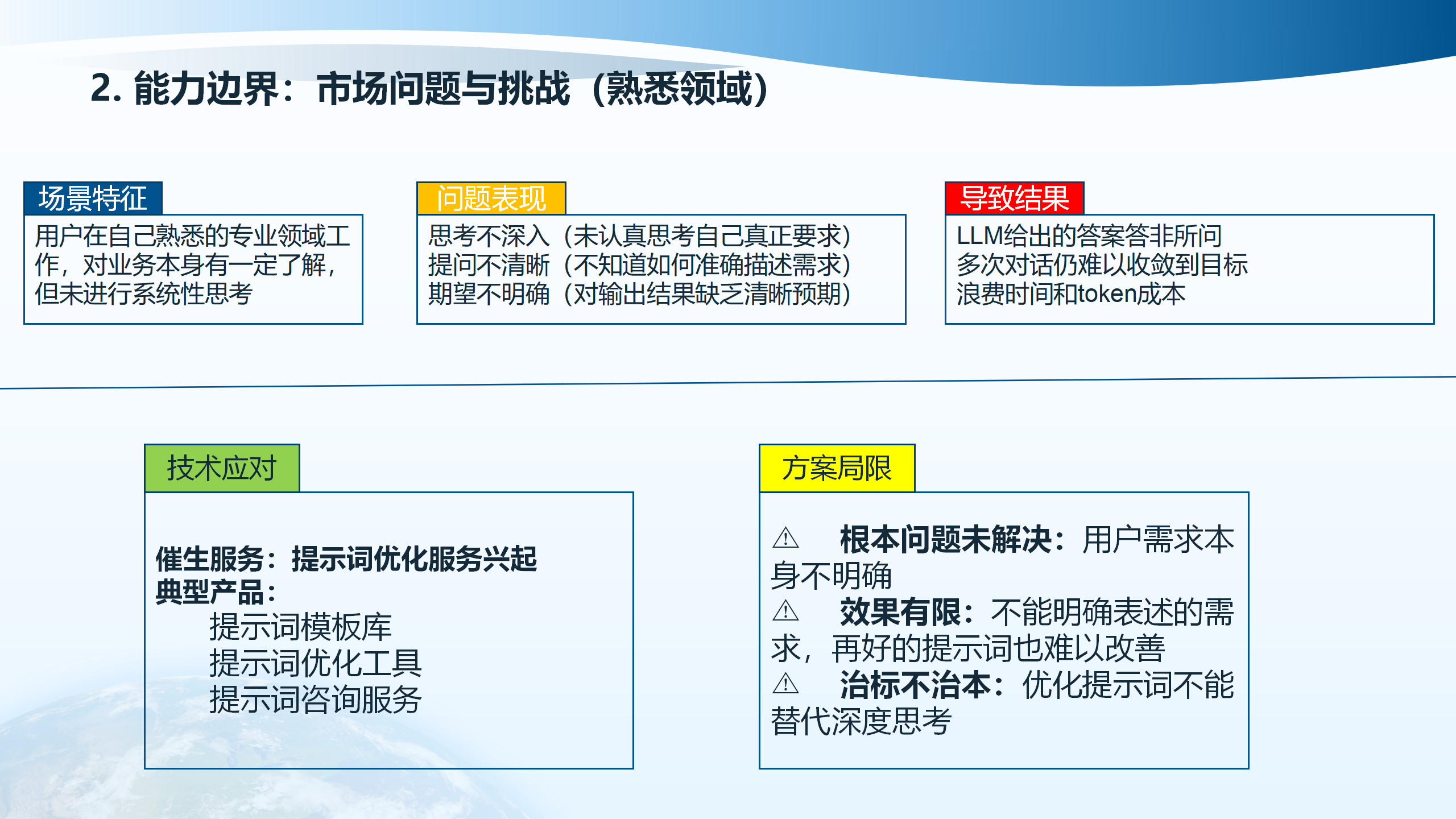
当用户在自己熟悉的专业领域工作时,虽然对业务本身有一定了解,但往往存在思考不深入、提问不清晰、期望不明确等问题。用户未认真思考自己真正的要求,不知道如何准确描述需求,对输出结果缺乏清晰预期。这种情况下,LLM给出的答案答非所问,多次对话仍难以收敛到目标,浪费时间和token成本。
催生服务如提示词优化服务应运而生,包括提示词优化工具和提示词咨询服务。然而,这些服务的效果有限,不能明确表述的需求,再好的提示词也难以改善。优化提示词不能替代深度思考,治标不治本。
2.4 市场问题与挑战:工具使用不足
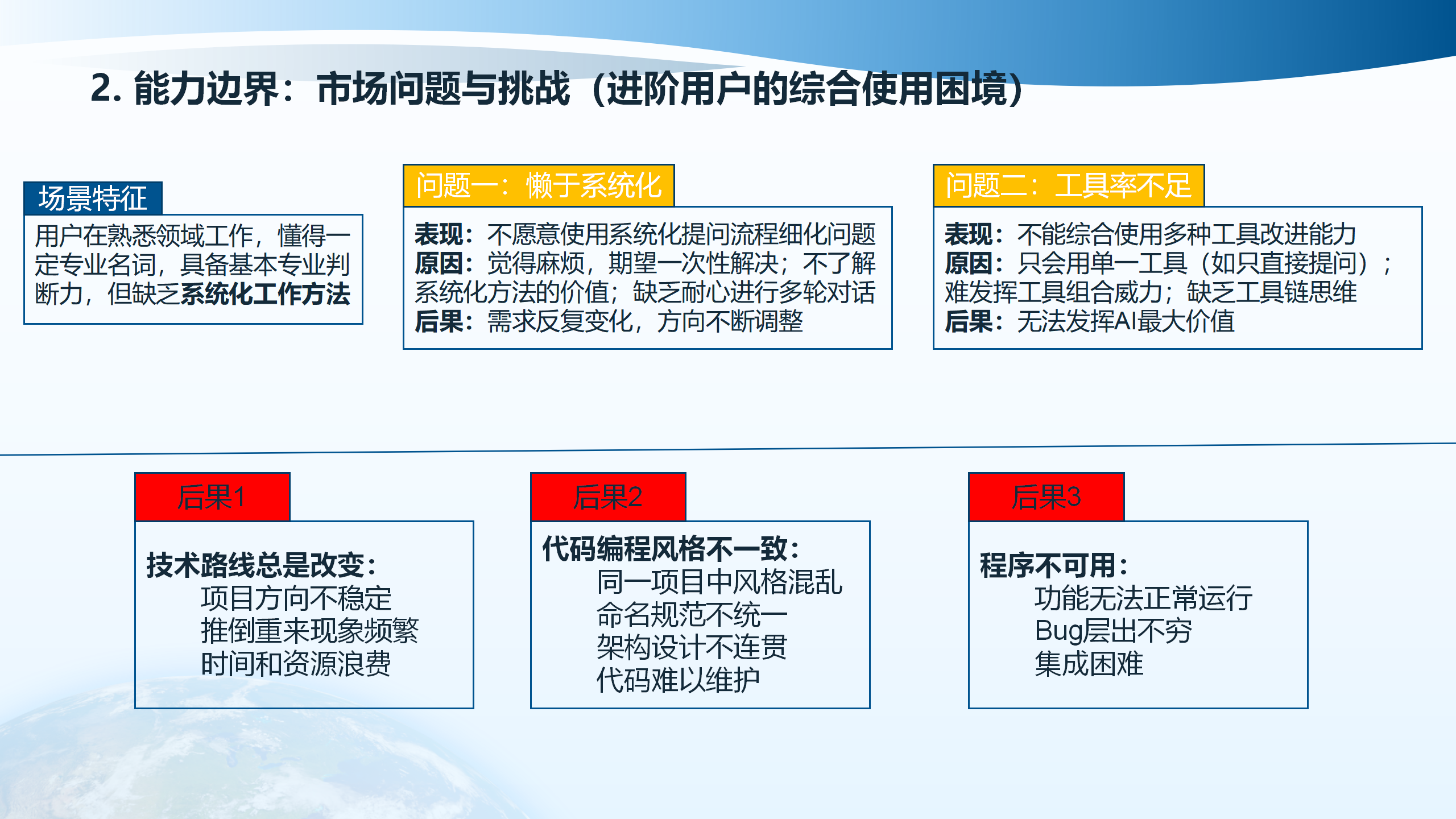
用户在熟悉领域工作时,懂得一定专业名词,具备基本专业判断力,但往往缺乏系统化工作方法。用户不愿意使用系统化提问流程细化问题,觉得麻烦,期望一次性解决,不了解系统化方法的价值,缺乏耐心进行多轮对话。用户只会用单一工具,如只直接提问,难以发挥工具组合威力,缺乏工具链思维。
这种情况下,需求反复变化,方向不断调整,技术路线总是改变,项目方向不稳定,时间和资源浪费,代码难以维护,功能无法正常运行,推倒重来现象频繁,集成困难。
2.5 行业解决方案
针对上述问题,业界提出了多种解决方案。方案一是ChatGPT的对话改进,通过提问引导用户思考,或其Study and Learn模式帮助用户明确需求。方案二是代码编辑器的增强模式,如Cursor,通过系统提示词设置全局编码规范,通过项目提示词设置项目特定规则,通过上下文感知理解项目结构。方案三是提示词工程化,如Prompts Project,通过提示词版本管理、提示词模板库、团队协作与共享等方式,实现提示词的规范化管理。
这些方案的核心思想是:需求不明时,通过提问引导用户思考;知识不足时,通过RAG等技术补充专业知识;鉴别能力弱时,通过系统化方法建立质量标准。通过这些方案,可以实现代码风格统一、架构一致性保障、长期能力培养。

2.6 AI不能做什么
AI不是万能的,需要正确使用。系统化是关键,需要避免随意性。流程要规范,需要保证质量稳定。能力要培养,需要持续学习改进。AI不能做用户没有能力鉴别正误的事情,不能替代深入思考需求,不能替代系统化工作方法,不能替代掌握多种工具,不能替代建立质量标准,不能替代培养鉴别能力。
AI是工具,不是万能。人的认知深度决定AI输出质量。专业性需要人工验证。只有通过深入思考需求、系统化工作方法、掌握多种工具、建立质量标准、培养鉴别能力,才能充分发挥AI在工程应用中的价值。
三、工程应用:AI在工程中的应用方式
3.1 AI在工程中的角色
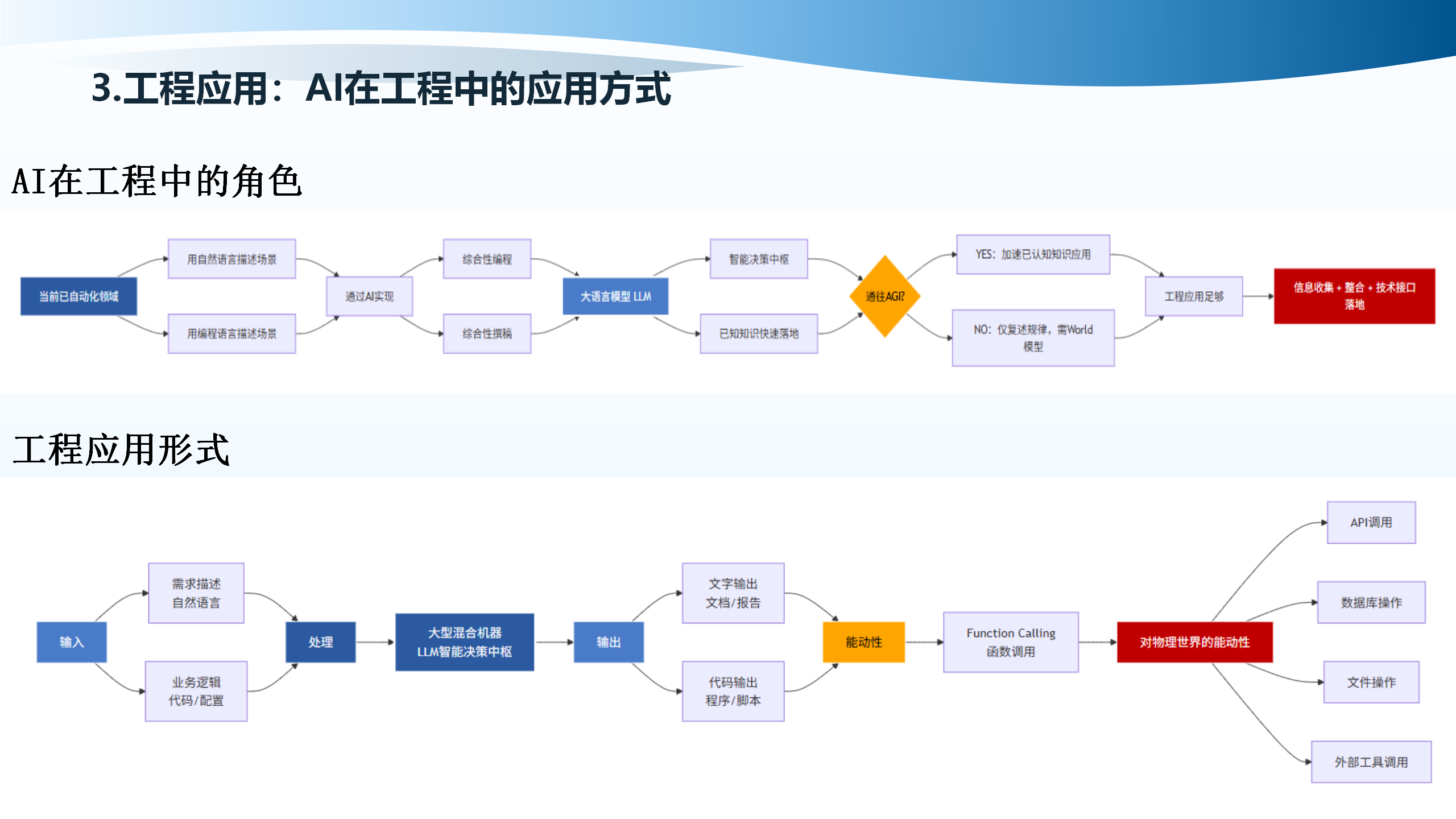
AI在工程中扮演着”已知知识快速落地”的角色。通过自然语言接口(Natural Language Interface),AI能够理解用户的需求描述,生成文字输出(文档/报告)或代码输出(程序/脚本)。AI本质上是一个大型混合机器,输入端接收自然语言需求描述、业务逻辑说明、技术规格要求、上下文信息、示例数据;处理过程包括理解语义和意图、调用内部知识、推理和规划、生成和优化;输出端包括文档、代码、分析等多种形式。
Function Calling是AI从”纸上谈兵”到”实际行动”的关键。通过Function Calling,AI可以调用外部工具,包括数据库操作、API接口调用、文件系统操作、网络请求等,实现自动化执行、任务调度自动化、流程编排自动化,甚至与物理世界交互,控制硬件设备,操作软件系统,与真实环境互动。
3.2 AI工程应用的适用场景
当前AI技术特别适用于那些已经基于初步编码实现自动化的领域,这些领域具有问题边界清晰、流程相对标准化、有成熟的解决范式等特点。在这些场景中,AI能够发挥知识整合能力、快速原型能力、应用落地能力等优势。
Function Calling带来的核心价值在于:这是90%专家认为LLM是通往AGI(Artificial General Intelligence,通用人工智能)路径的核心原因。知识整合能力使得AI能够整合人类历史上积累的大量知识,实现跨领域知识融合,快速检索和应用。快速原型能力使得从想法到实现的周期大幅缩短,从方案到文档的效率大幅提升,从需求到代码的自动化程度提高。应用落地能力使得AI能够将抽象概念转化为具体实现,将专业知识转化为可执行方案,将业务需求转化为技术方案。

四、综合撰稿:AI辅助文档生成实践
4.1 综合撰稿流程
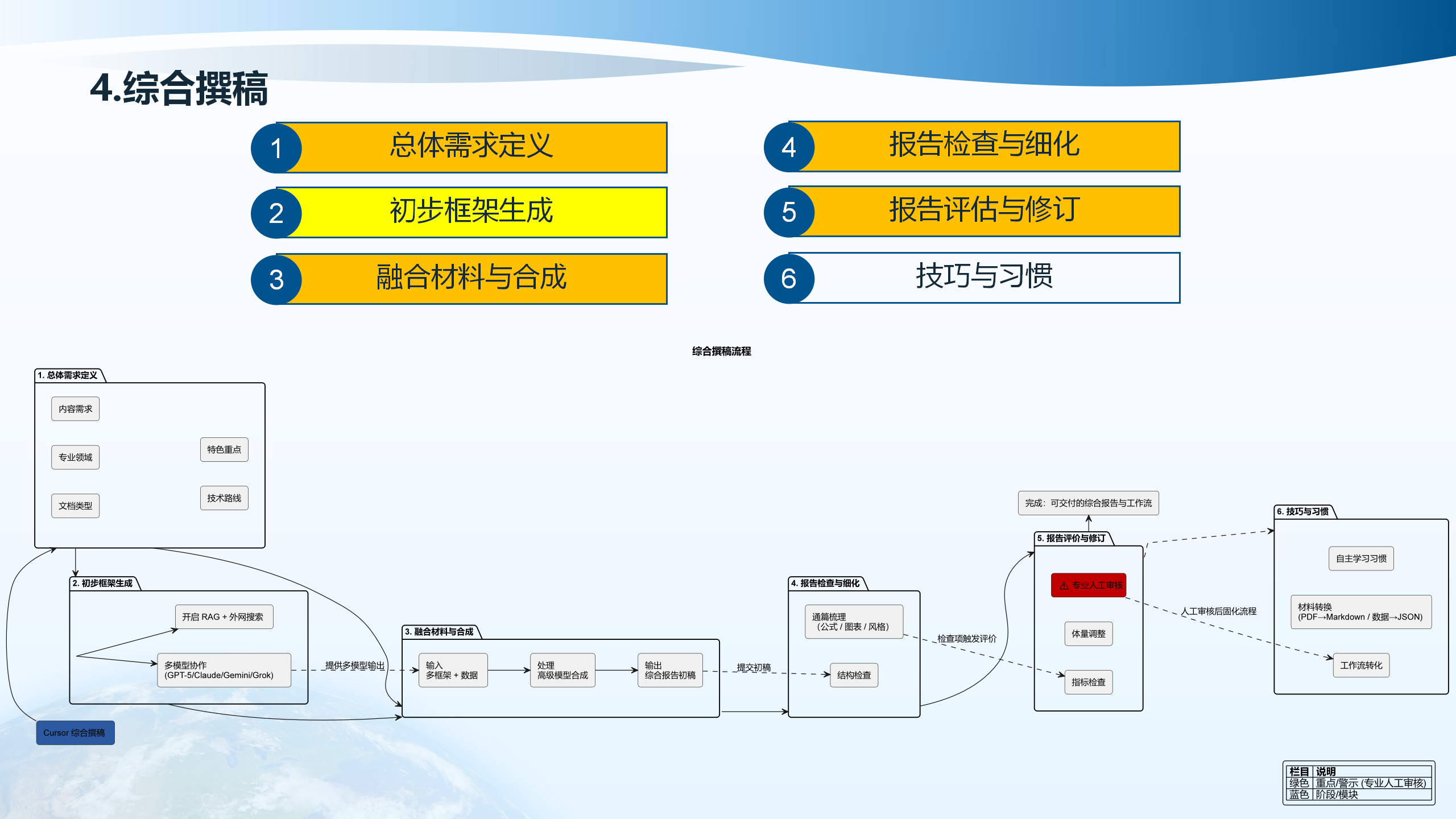
4.2 总体需求定义
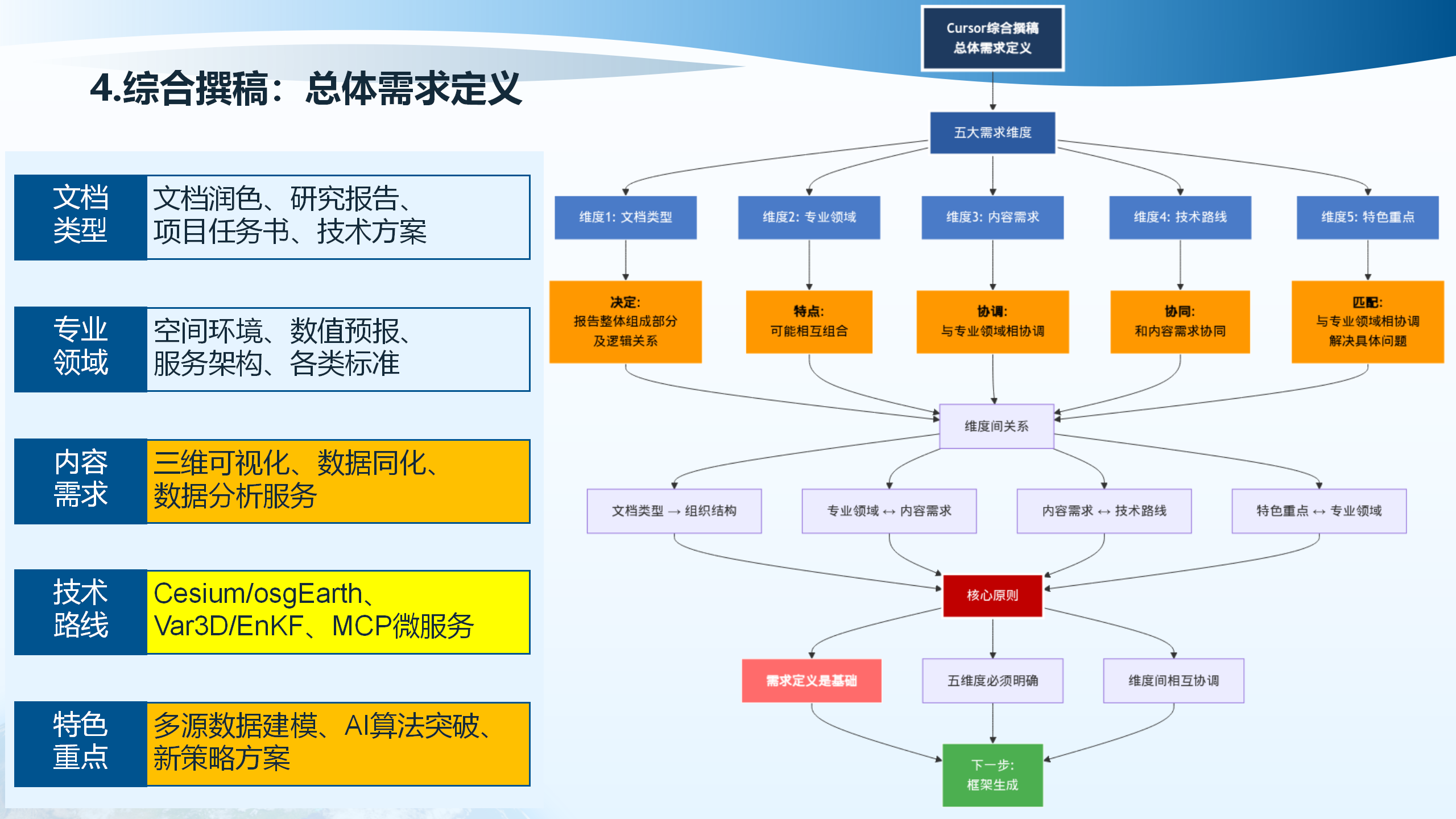
总体需求定义需要明确多个维度:文档类型(文档润色、研究报告、技术文档等)、组织结构(章节划分、内容层次)、专业领域(空间环境、数值预报、服务架构、各类标准等)、内容需求(技术路线、特色重点等)。这些维度之间需要相互协调,确保文档的完整性和一致性。
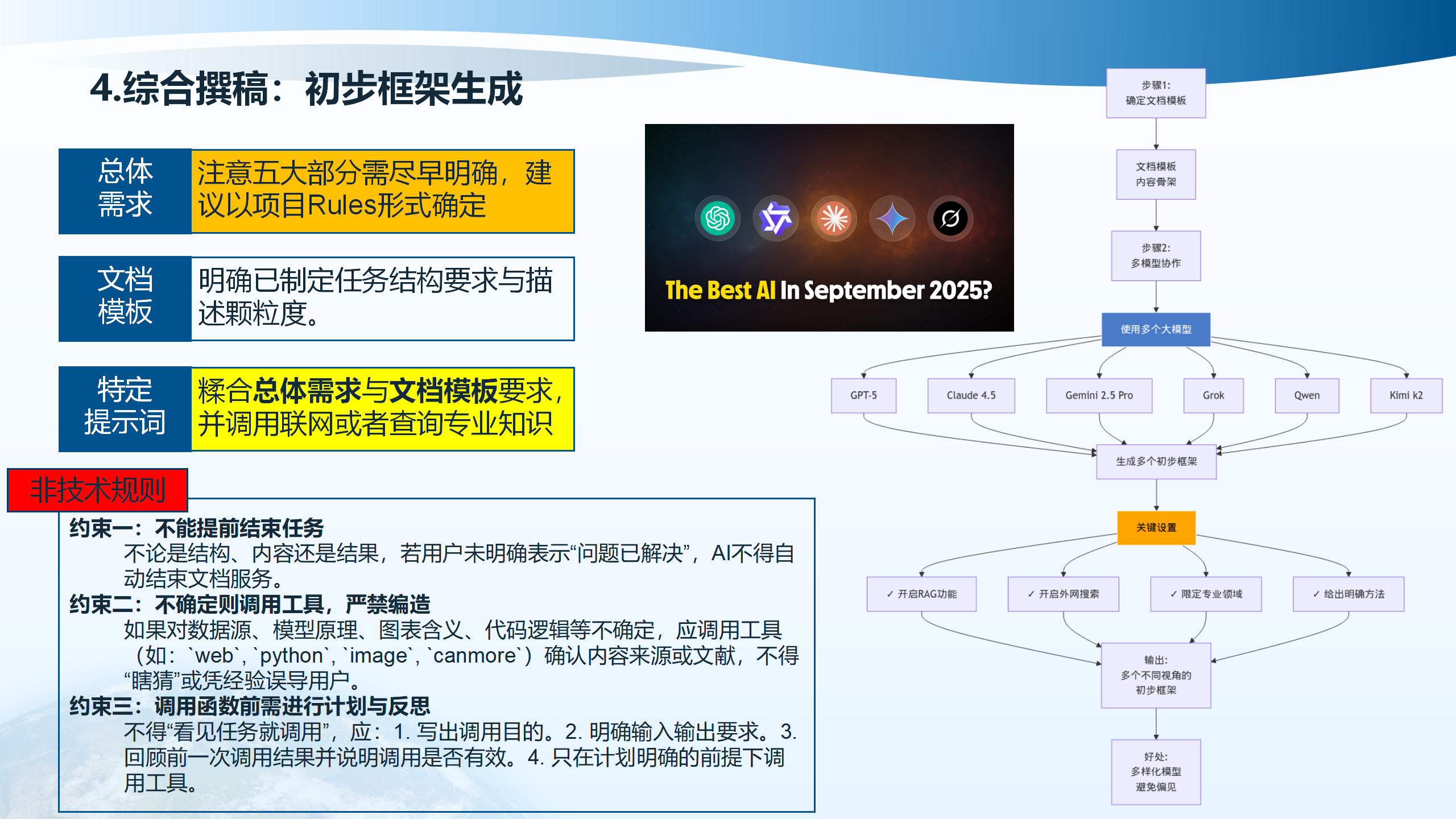
4.3 初步框架生成
初步框架生成包括两个步骤:步骤一是确定文档模板,步骤二是多模型协作生成特定框架。在生成过程中,需要遵循三个约束:约束一是不能提前结束任务,不论是结构、内容还是结果,若用户未明确表示”问题已解决”,AI不得自动结束文档服务。约束二是不确定则调用工具,严禁编造,如果对数据源、模型原理、图表含义、代码逻辑等不确定,应调用工具确认内容来源或文献,不得”瞎猜”或凭经验误导用户。约束三是调用函数前需进行计划与反思,不得”看见任务就调用”,应写出调用目的、明确输入输出要求、回顾前一次调用结果并说明调用是否有效、只在计划明确的前提下调用工具。
关键设置包括:限定专业领域、明确方法、开启RAG功能、开启外网搜索、全面使用准备材料、避免偏见。
4.4 融合材料与合成
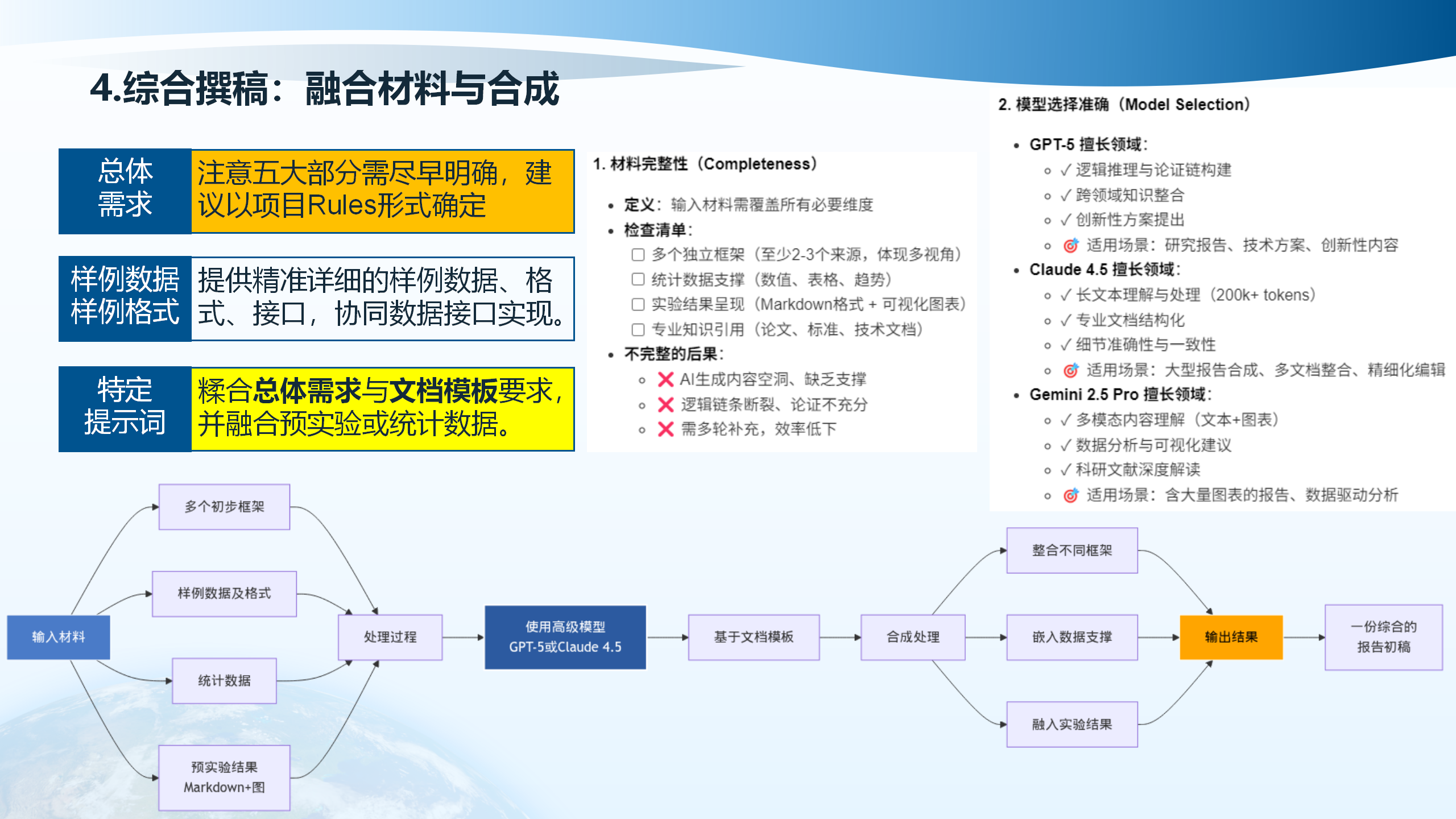
融合材料与合成阶段需要确保材料完整性。输入材料需覆盖所有必要维度,包括多个独立框架(至少2-3个来源,体现多视角)、提供精准详细的样例数据、格式、接口,协同数据接口实现。不完整的后果包括AI生成内容空洞、缺乏支撑、逻辑链条断裂、论证不充分。
模型选择需要准确。GPT-5擅长逻辑推理与论证链构建、创新性方案提出、实验结果呈现(Markdown格式+可视化图表)、专业知识引用(论文、标准、技术文档)。Claude擅长多文档整合、精细化编辑、多模态内容理解(文本、图表)、数据分析与可视化建议、科研文献深度解读。
处理过程包括:多个初步框架、样例数据及格式、统计数据、融入实验结果、预实验结果(Markdown+图),最终生成一份综合的报告。
4.5 报告检查与细化
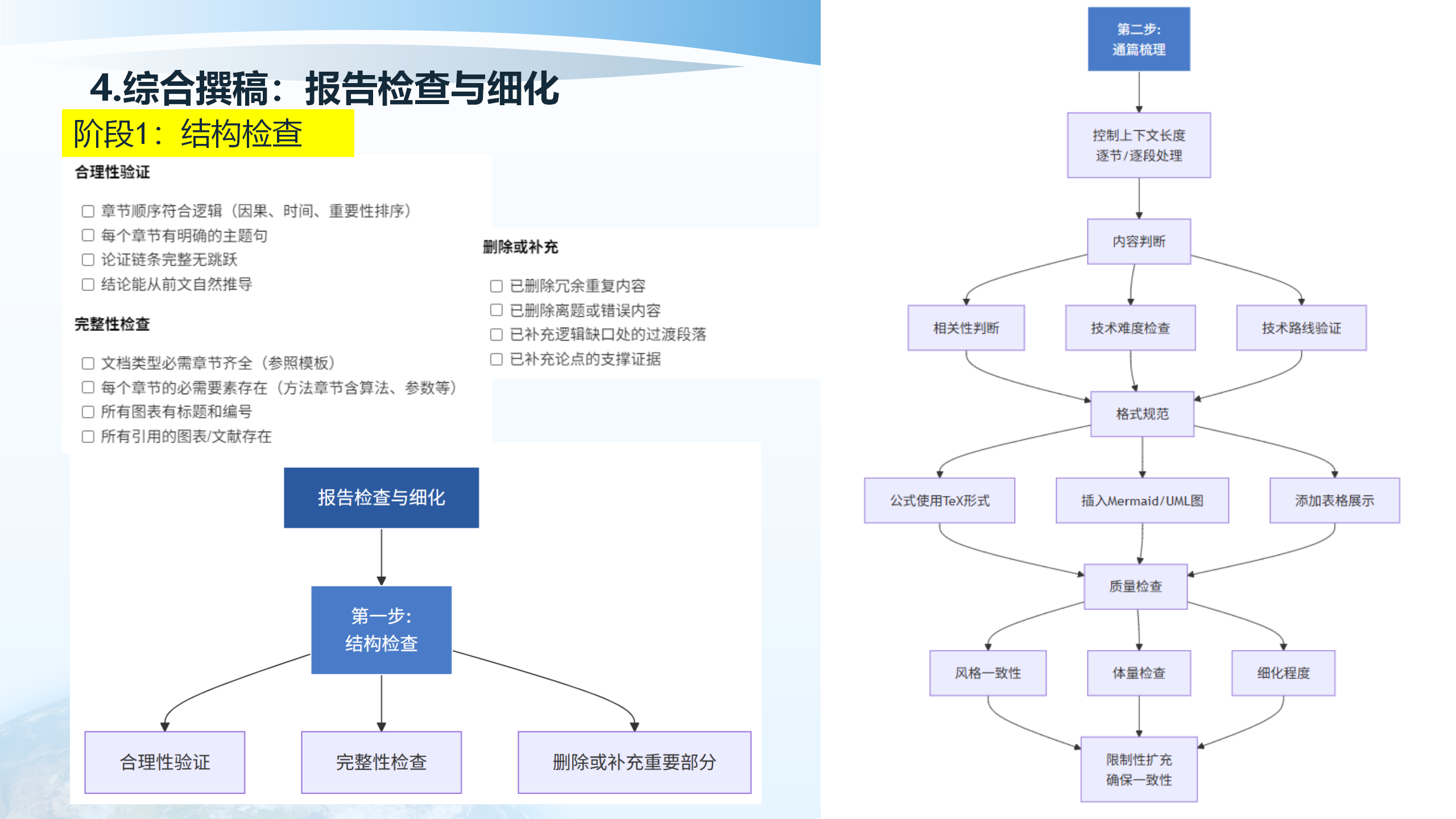
报告检查与细化包括多个方面:合理性验证(章节顺序符合逻辑、每个章节有明确的主题句、论证链条完整无跳跃、结论能从前文自然推导)、完整性检查(文档类型必需章节齐全、每个章节的必需要素存在、所有图表有标题和编号、所有引用的图表/文献存在)、结构检查(格式规范、风格一致性、细化程度)、内容判断(相关性判断、技术难度检查、技术路线验证)。
格式规范包括:公式使用TeX形式(行内公式,独立行公式)、插入Mermaid/UML图(流程图、架构图、时序图)、添加表格展示(对比数据、参数列表、实验结果)。
4.6 报告检查与细化:通篇梳理
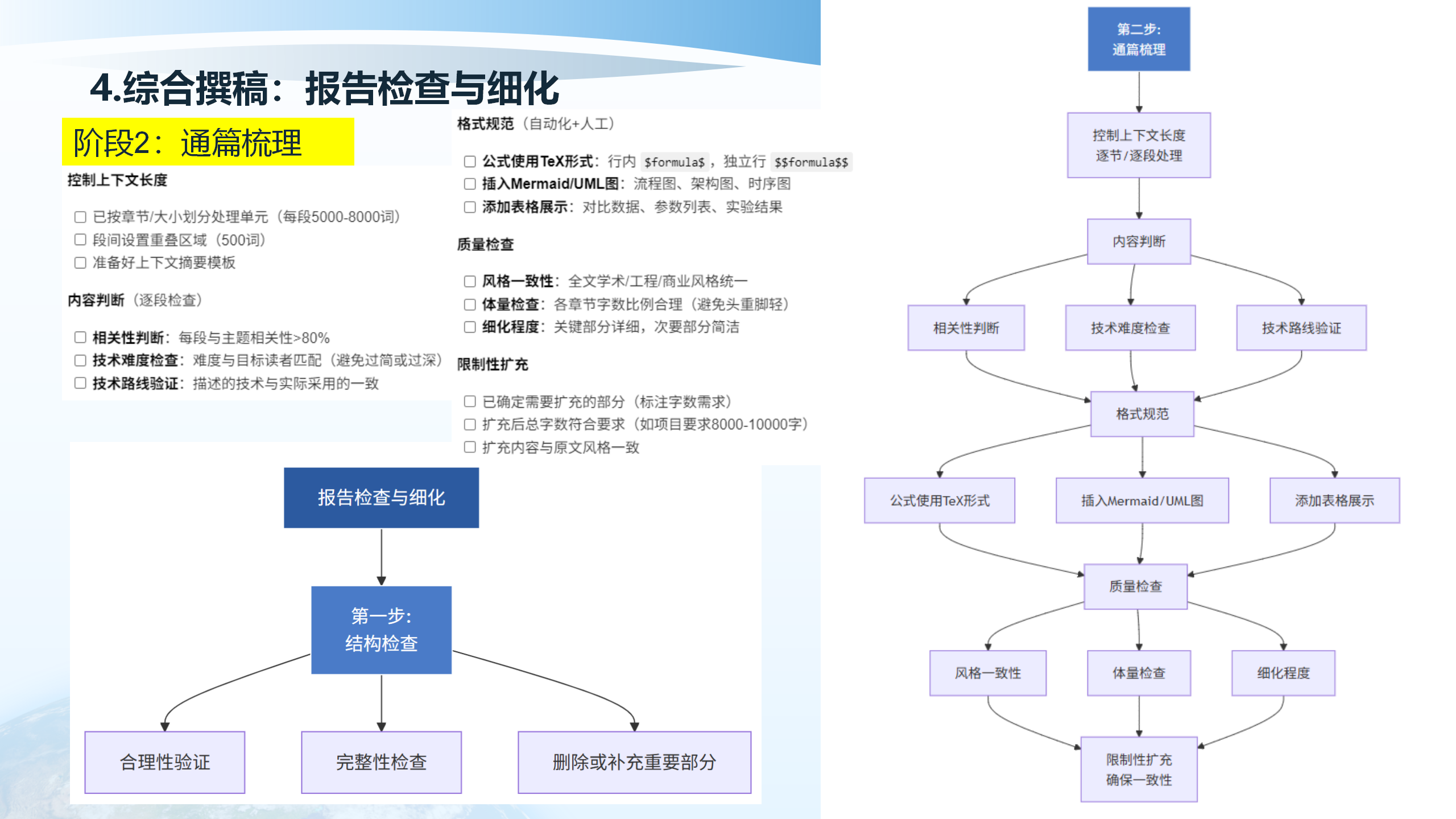
通篇梳理阶段需要控制上下文长度,按章节/段落划分处理单元(每段5000-8000词),段间设置重叠区域(500词),准备好上下文摘要模板。内容判断包括相关性判断(每段与主题相关性>80%)、技术难度检查(难度与目标读者匹配,避免过简或过深)、技术路线验证(描述的技术与实际采用的一致)。
格式规范(自动化+人工)包括:公式使用TeX形式、插入Mermaid/UML图、添加表格展示。质量检查包括:风格一致性(全文学术/工程/商业风格统一)、体量检查(各章节字数比例合理,避免头重脚轻)、细化程度(关键部分详细,次要部分简洁)。限制性扩充包括:确定需要扩充的部分(标注字数需求)、扩充后总字数符合要求、扩充内容与原文风格一致。
4.7 报告检查与细化:专业深化
专业深化阶段包括多个轮次:轮次1是语言润色(无语法错误、表达流畅、词汇多样),轮次2是ERB(论证链图已绘制并验证、孤立论点已补充连接、因果关系已检验),轮次3-5是专业深化(已补充最近2年文献至少3篇、关键算法有详细描述公式/伪代码、与SOTA方法有定量对比表、创新点明确列出3-5个)。
退出检查包括:量化指标达标(语法错误率、一致性等)、专家评审通过(至少2位专家)、技术负责人确认、非专业人士可理解性测试通过。
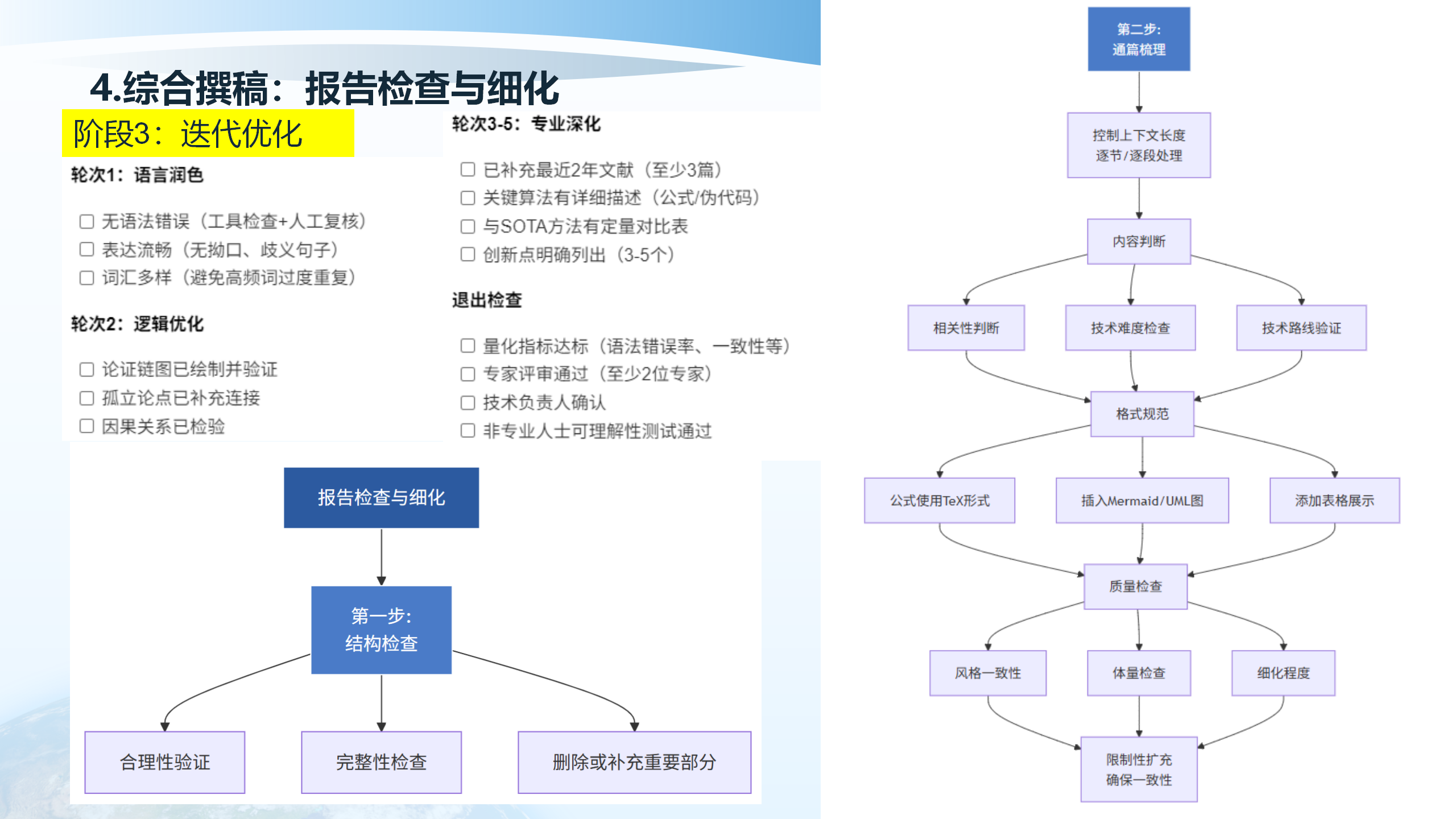
4.8 报告评价与修订
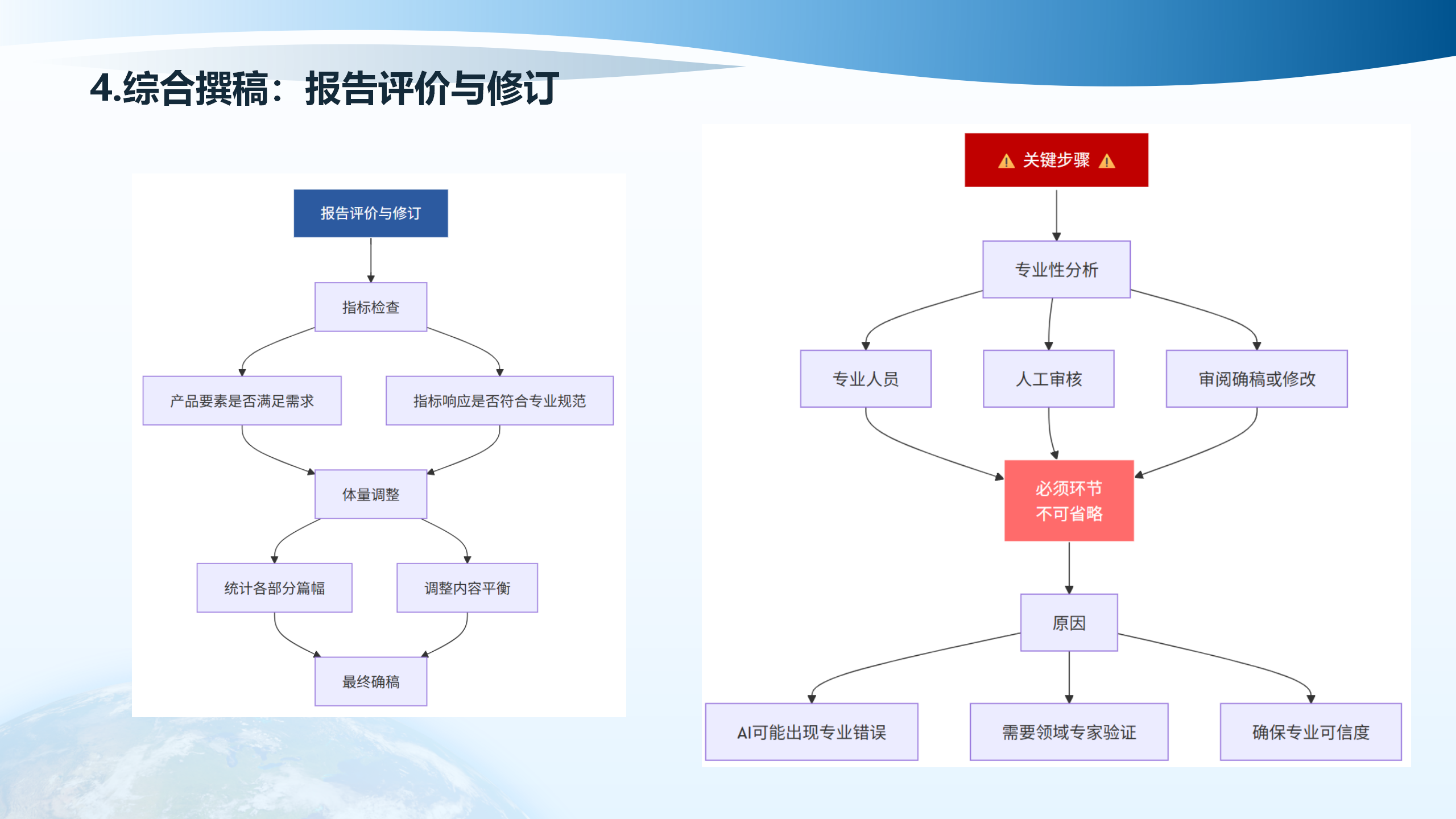
报告评价与修订包括多个方面:指标检查(产品要素是否满足需求、指标响应是否符合专业规范)、体量调整(统计各部分篇幅、调整内容平衡)、专业性分析(专业人员人工审核、审阅确稿或修改)。这是必须环节,因为AI可能出现专业错误,需要领域专家验证,确保专业可信度。
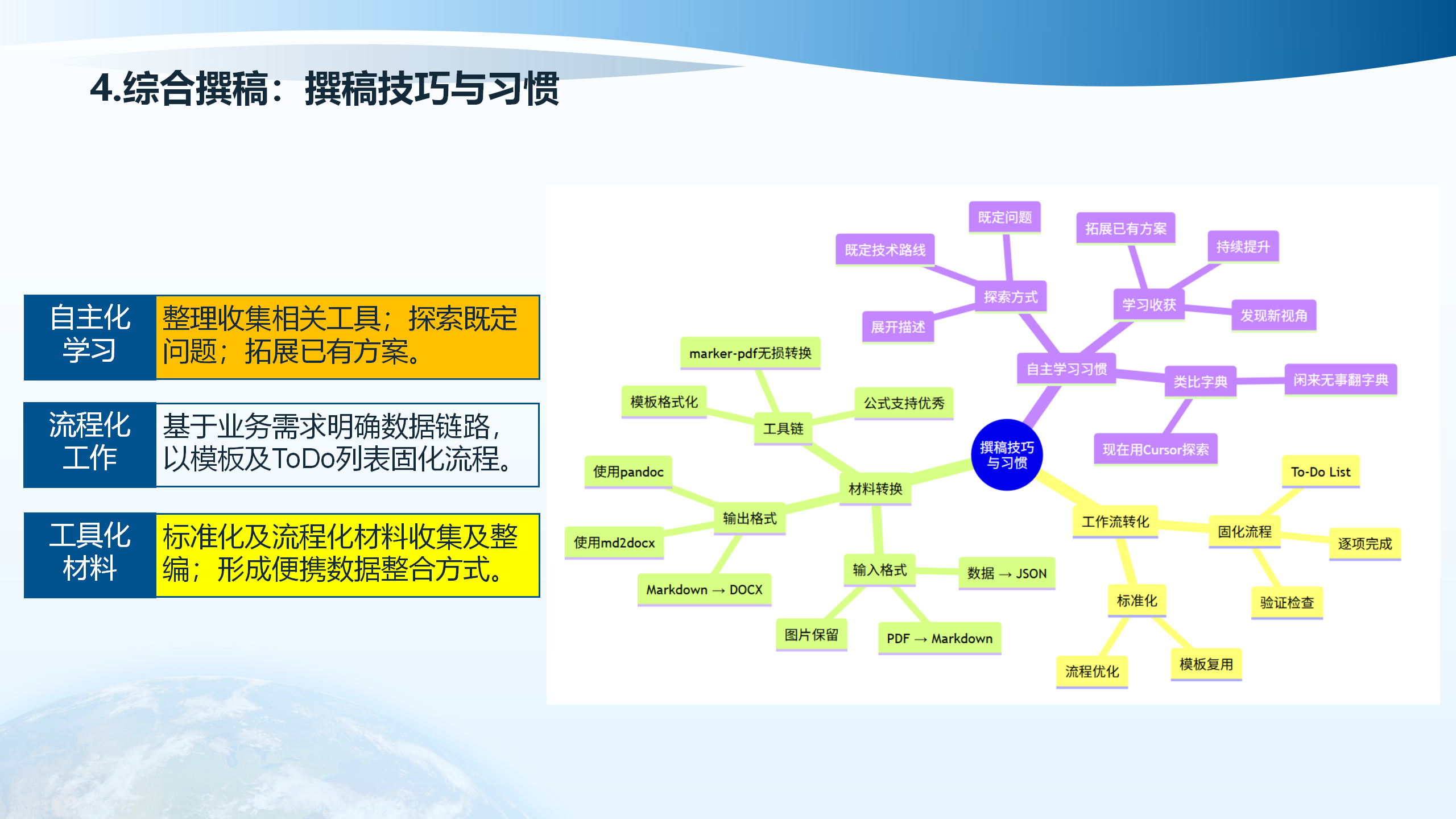
4.9 撰稿技巧与习惯
撰稿技巧与习惯包括:发现新视角、展开描述、自主学习习惯。过去是”闲来无事翻字典”,现在用Cursor探索。基于业务需求明确数据链路,以模板及ToDo列表固化流程。
五、综合编程:AI辅助软件开发实践
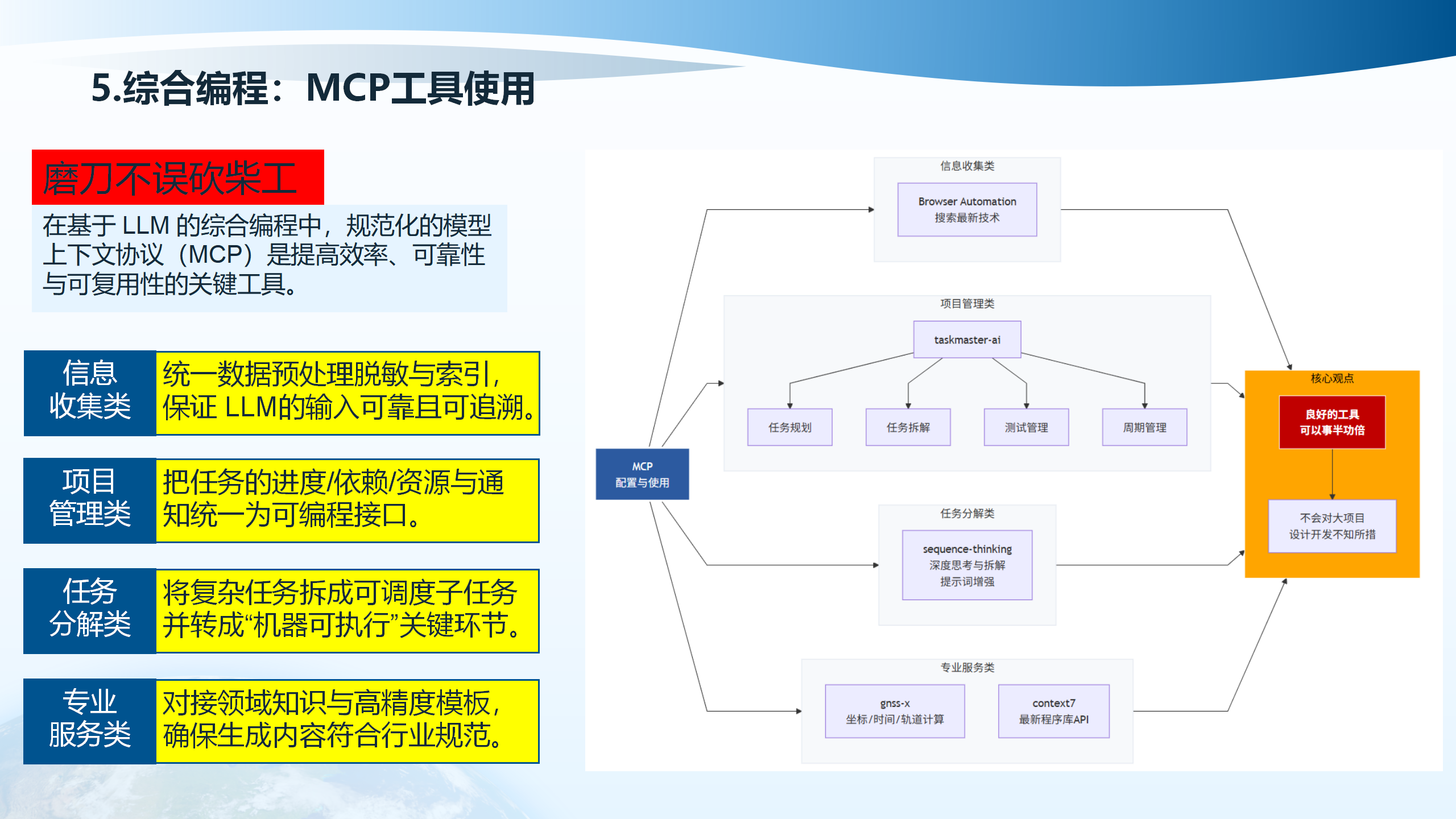
5.1 MCP工具使用
在基于LLM的综合编程中,规范化的模型上下文协议(Model Context Protocol, MCP)是提高效率、可靠性与可复用性的关键工具。MCP工具包括项目管理类(taskmaster-ai,包括任务规划、任务拆解、测试管理、周期管理)、分解类(sequence-thinking,包括深度思考与拆解)、提示词增强、专业服务类(gnss-x,包括坐标/时间/轨道计算;context7,包括最新程序库API)。
5.2 综合编程
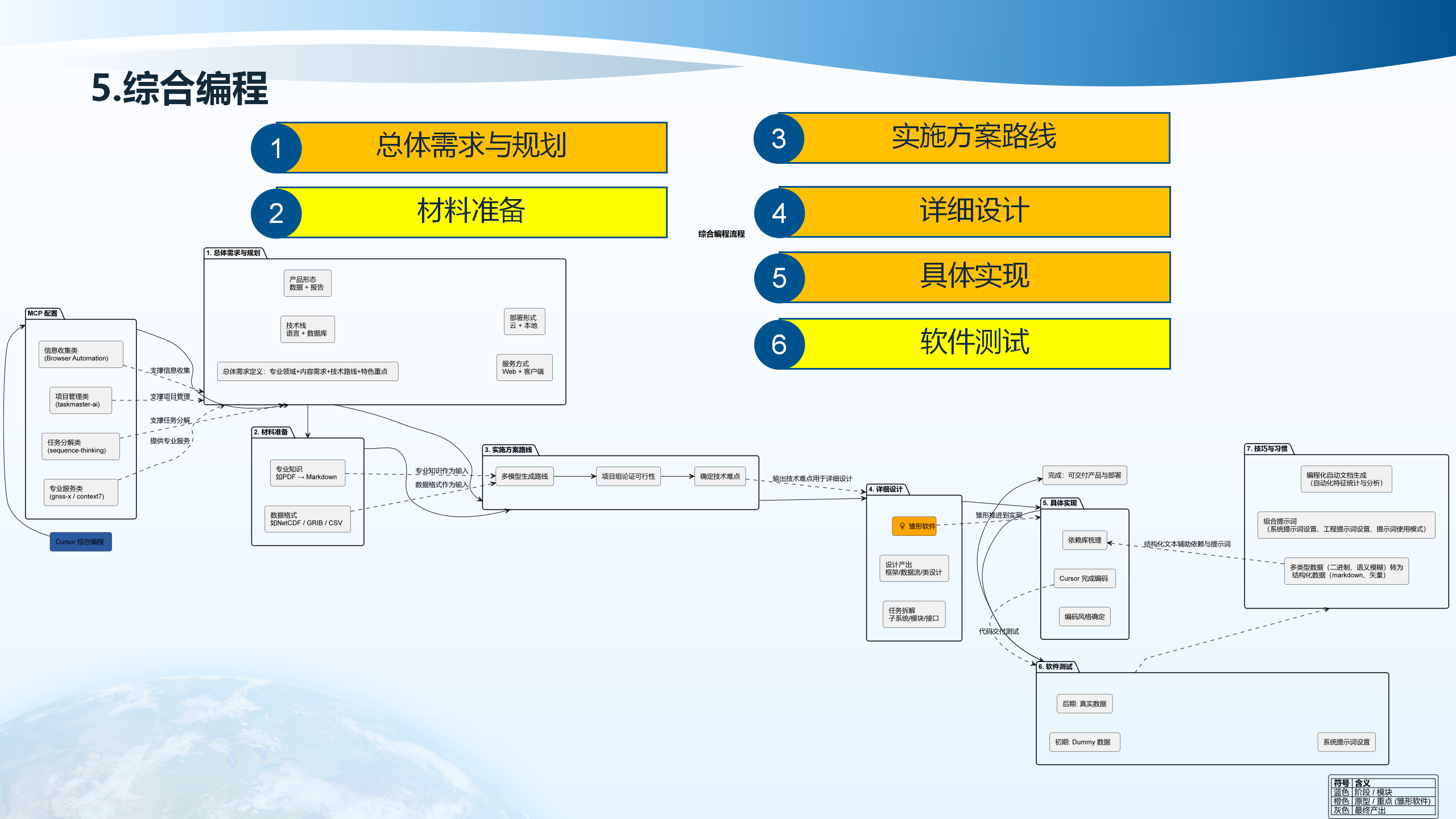
5.3 总体需求与规划
总体需求与规划需要明确多个方面:文档类型、任务规划、部署方式(什么部署)、编程语言(什么语言)、产品形式(什么产品)、服务形式(什么服务)、数据库选择(什么数据库)。产品形式包括数据产品、图文报告、客户端应用、远程服务、本地服务等。
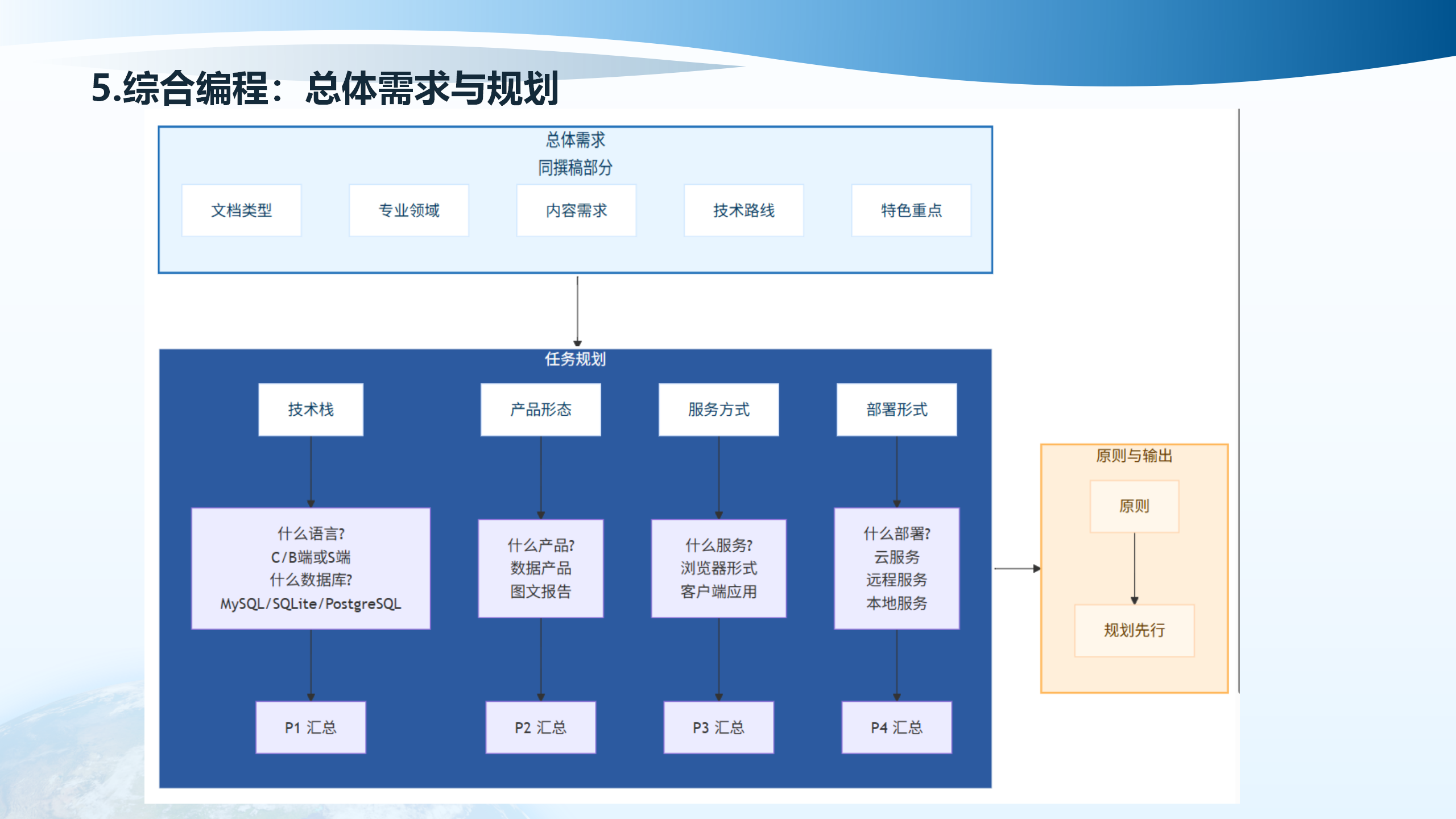
5.3 材料准备
材料准备包括方法学选择、参考论文与最佳实践。项目代码及技术说明文件的价值包括:可行性快速验证、技术栈选型依据、架构模式学习、性能预期评估、提供上下文给LLM、Cursor提示词增强、单元测试参考、持续集成配置、标准化文档生成、代码审查标准。
相关论文及项目文档的价值包括:算法对比分析、技术成熟度评估、参数配置指导、依赖条件明确、性能基准建立、失败案例学习、精度指标量化、技术报告撰写、数据需求明确、算法原理说明、计算资源评估、团队技能提升。
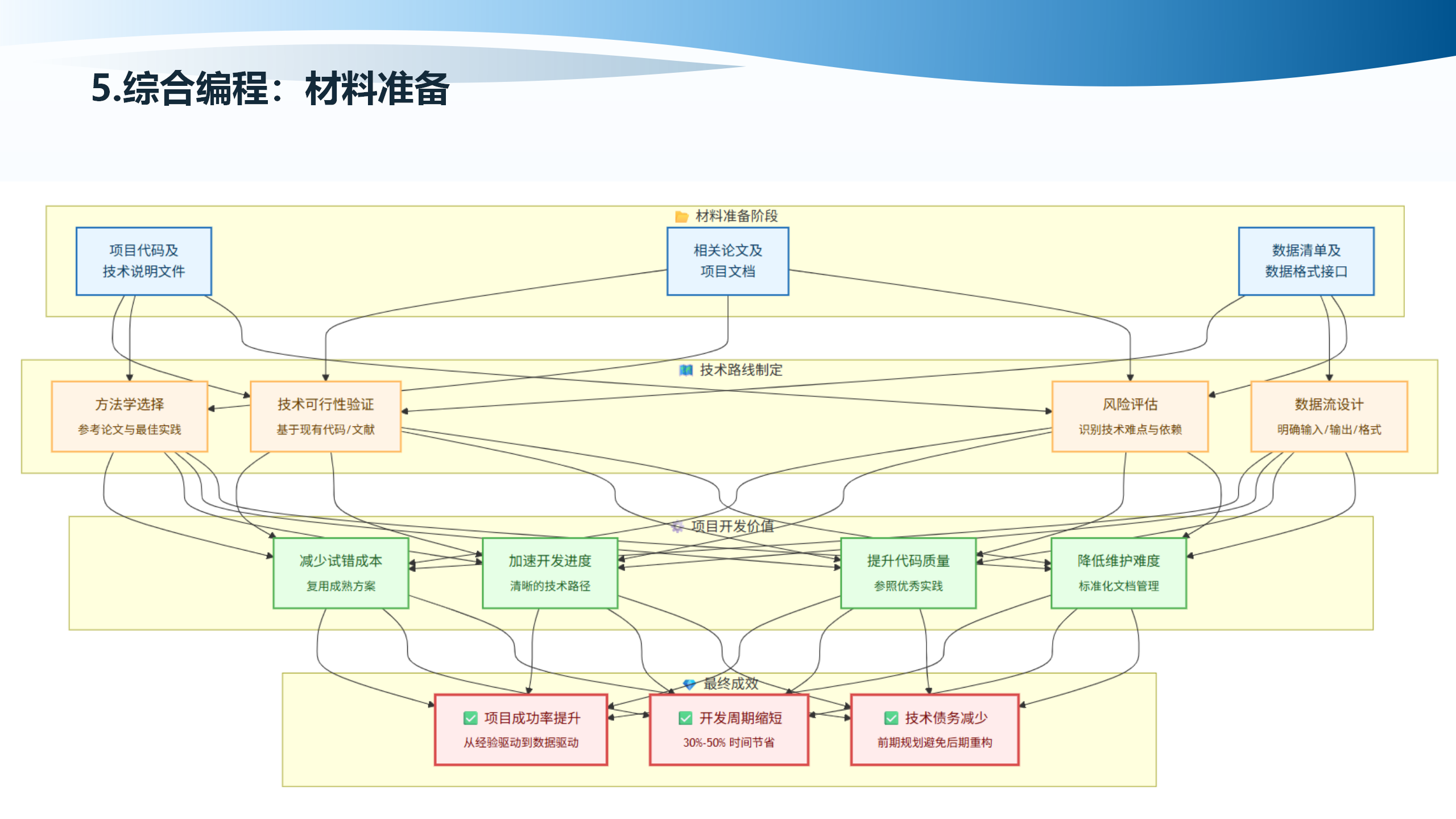
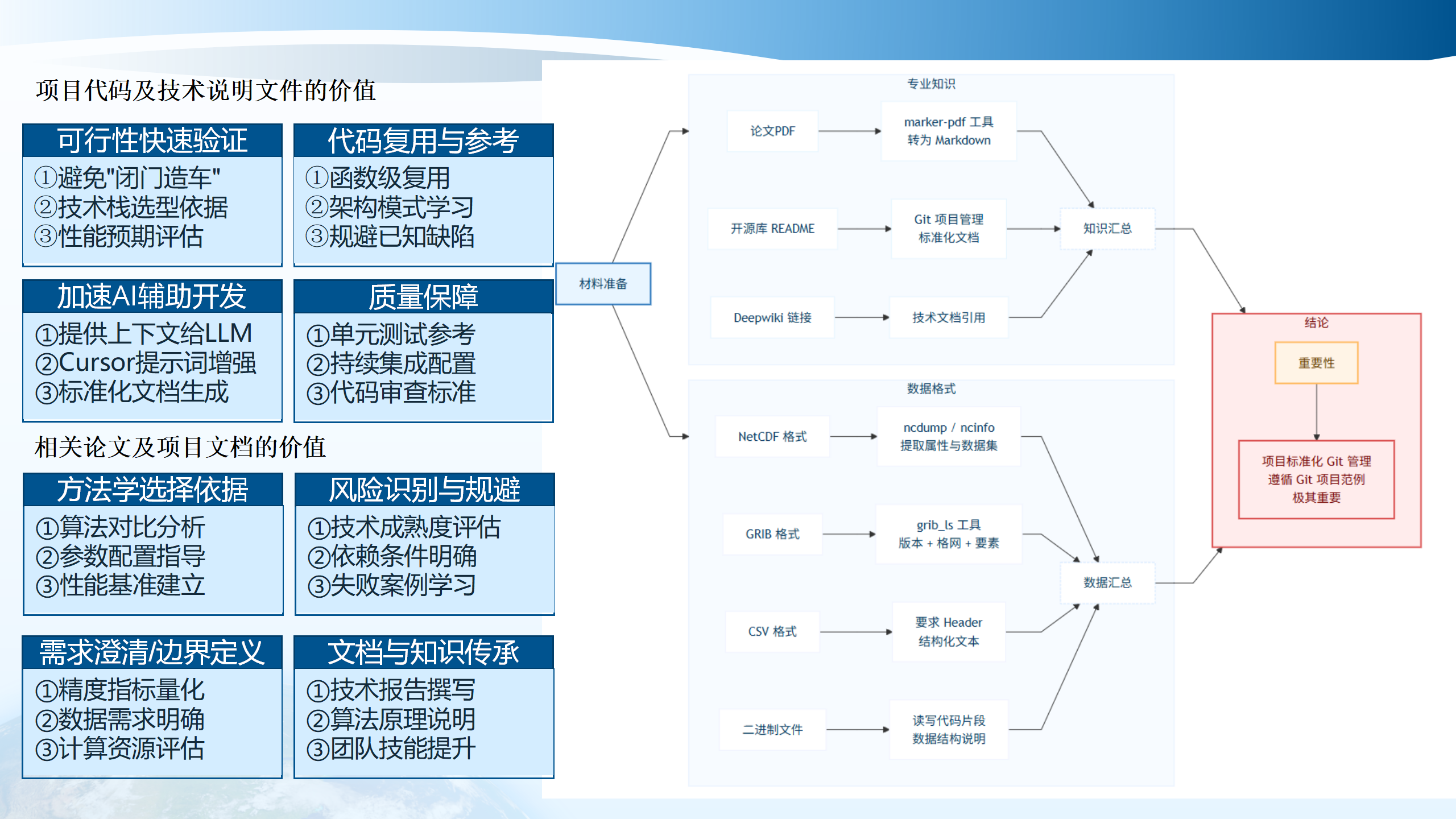
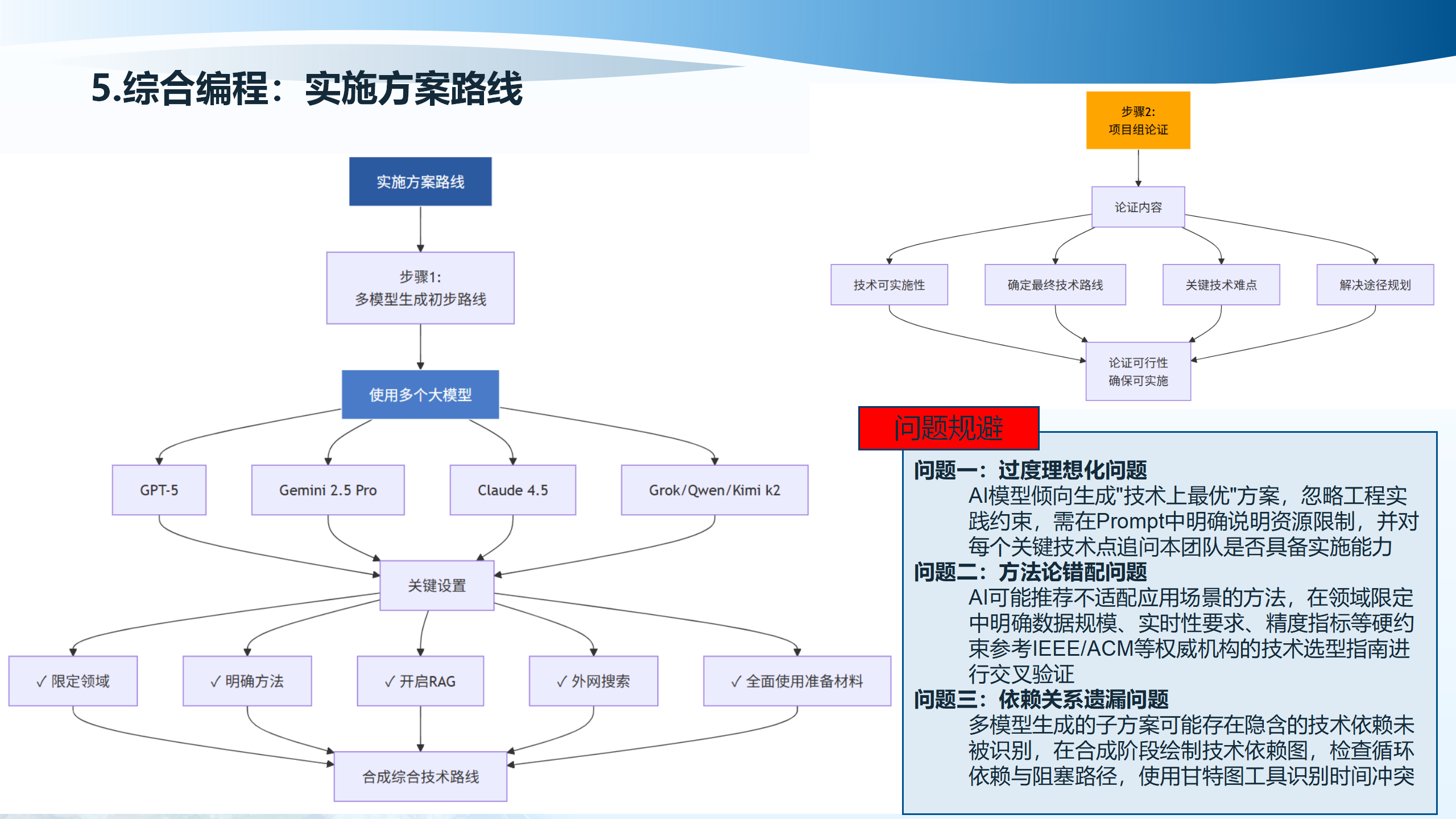
5.4 实施方案路线
实施方案路线包括多个步骤:步骤一是多模型生成初步路线,通过GPT-5、Gemini 2.5 Pro、Claude 4.5、Grok/Qwen/Kimi等多模型协作,确保技术可实施性、确定最终技术路线、识别关键技术难点、规划解决途径。
需要注意的问题包括:问题一是过度理想化问题,AI模型倾向生成”技术上最优方案”,忽略工程实践约束,需在Prompt中明确说明资源限制,并对每个关键技术点追问本团队是否具备实施能力。问题二是方法论错配问题,AI可能推荐不适配应用场景的方法,在领域限定中明确数据规模、实时性要求、精度指标等硬约束,参考IEEE/ACM等权威机构的技术选型指南进行交叉验证。问题三是依赖关系遗漏问题,多模型生成的子方案可能存在隐含的技术依赖未被识别,在合成阶段绘制技术依赖图,检查循环依赖与阻塞路径,使用甘特图工具识别时间冲突。
关键设置包括:限定领域、明确方法、开启RAG、外网搜索、全面使用准备材料。
5.5 详细设计
明确的详细设计是雏形软件的设计框架,具体且可规划。详细设计包括子系统划分、数据流设计、功能模块设计。设计先行,编码之前明晰、专业、精准,保障后续研发。工具支持包括Cursor辅助快速完成设计。
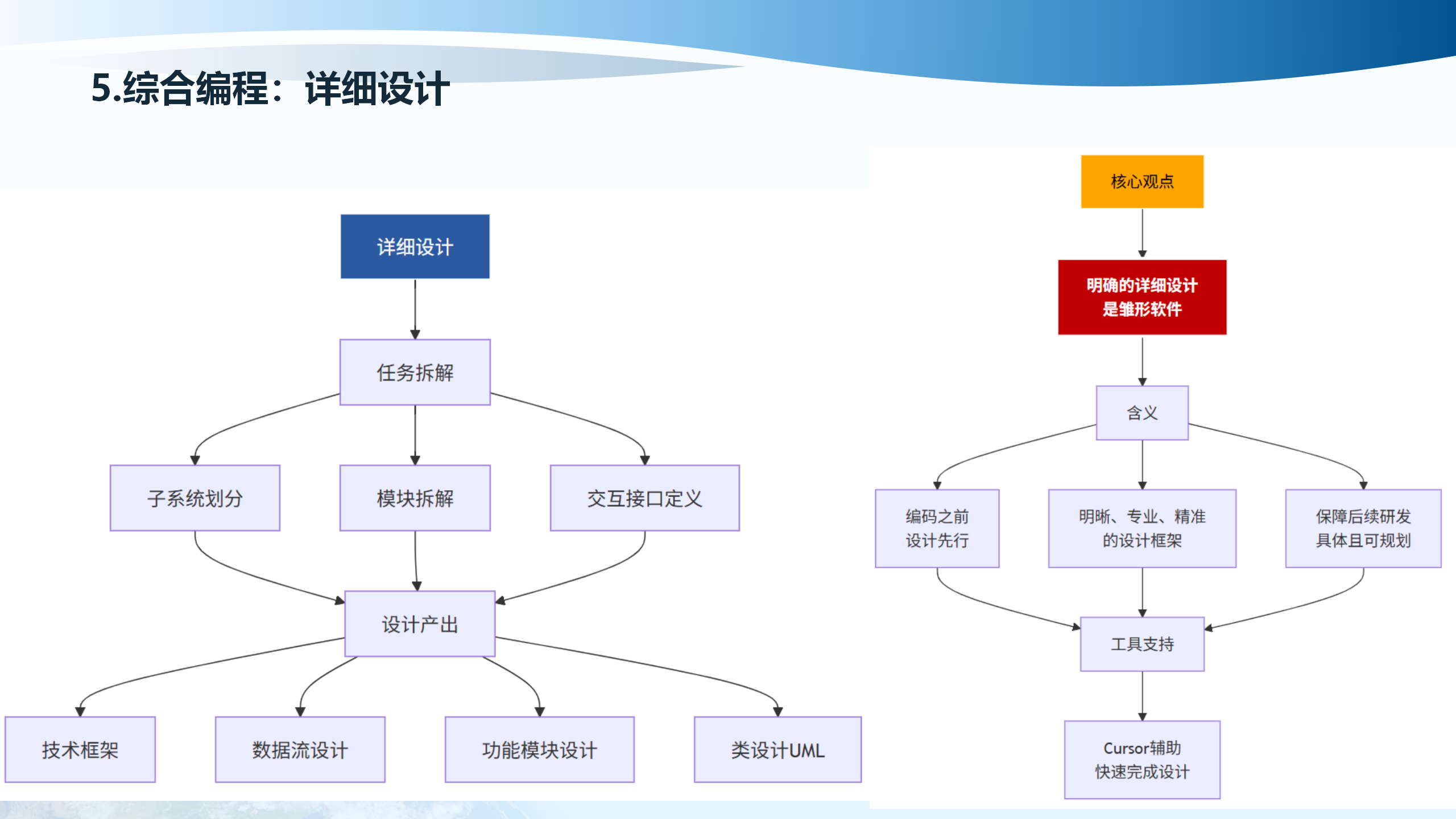
5.6 具体实现:设计产出物到编码规范的映射
阶段1是将设计产出物映射到编码规范。技术框架对应项目目录结构,根据C++/Python/Fortran模块划分创建目录树,使用CMake规范。数据流设计对应接口定义文件,定义模块间数据传递的头文件/接口类,使用pybind11暴露C++函数到Python。功能模块设计对应类/函数命名规范,遵循snake_case(函数/变量)、PascalCase(类)。类设计UML对应代码框架,生成带Doxygen注释的头文件与空实现,包含完整Doxygen注释和include guard。
命名规范、注释规范、依赖关系、算法复杂度一致性、满足需求情况下函数拆分实现、明确功能与I/O,良好的提示词不会有变化的编码风格。
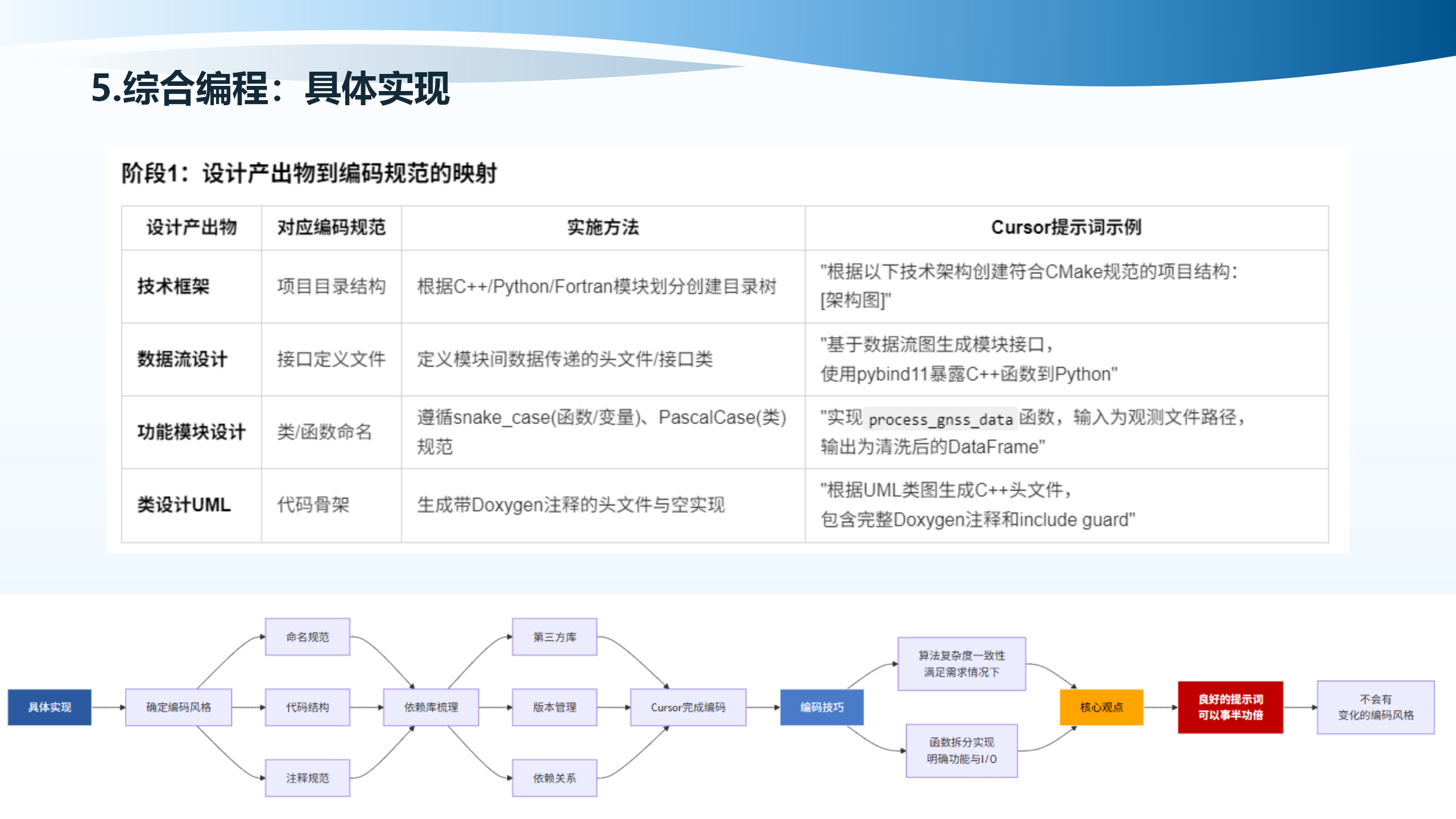
5.7 具体实现:编码风格一致性保障机制
阶段2是编码风格一致性保障机制。命名规范执行策略包括:变量使用snake_case(示例:gnss_observation_data),函数使用snake_case+动词开头(示例:calculate_ionospheric_delay()),类使用PascalCase(示例:SatelliteOrbitCalculator),常量使用UPPER_CASE(示例:MAX_SATELLITE_COUNT),布尔变量使用is_/has_/should_前缀(示例:is_valid_ephemeris)。
代码结构标准化包括:Include顺序(本模块→标准库→第三方库→项目库),使用include guard(如_GNSS_DATAPROCESSOR_H_风格)。
注释规范与自动化文档包括:C++使用Doxygen(/** */),Python使用Google风格文档字符串,Fortran使用!>格式的模块说明。要求Cursor在生成每个函数时同步生成文档注释,而非事后补充。
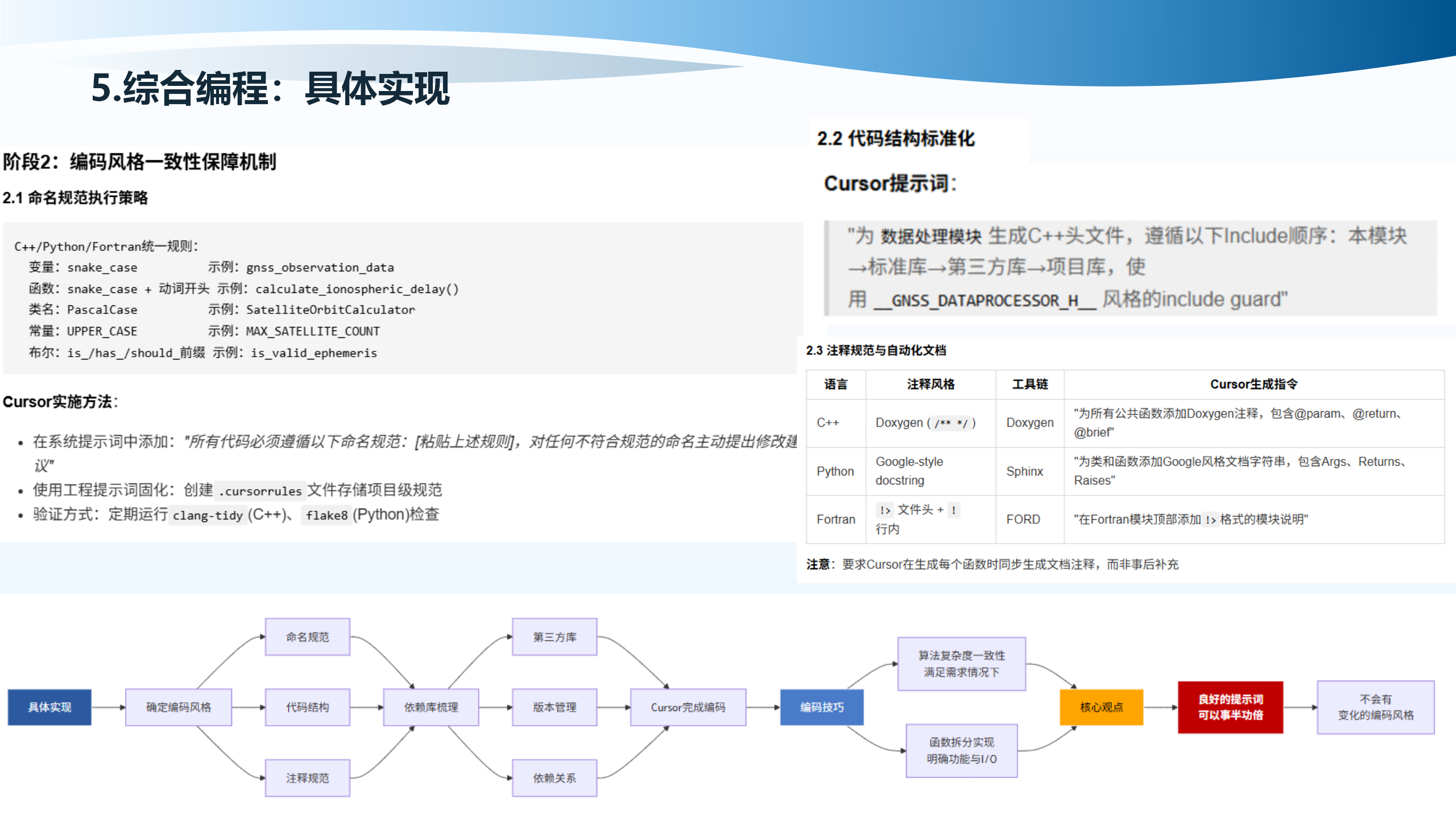
5.8 具体实现:依赖库梳理与管理
阶段3是依赖库梳理与管理。C++项目(CMakeLists.txt)包括:find_package(OpenBLAS 0.3.0 REQUIRED),find_package(pybind11 2.16.6 REQUIRED),第三方库路径设置。
允许使用的库(符合项目规范)包括:数值计算(OpenBLAS/LAPACK,唯一允许的数值库),GUI(ImGui、ImPlot、ImPlot3D,预编译库存于gui/lib),Python绑定(pybind11,用于C++接口暴露),测试框架(CTest(C++)、pytest(Python))。
禁止使用的库包括:任何需要额外数值库依赖的库(如BoostMath替代方案),非MIT/Apache 2.0开源协议的库。
版本锁定与兼容性策略包括:C++库通过CMake的find_package指定最低版本,Python库使用requirements.txt精确锁定版本(==而非>=),定期审查依赖的CVE漏洞(使用pip-audit或safety工具)。
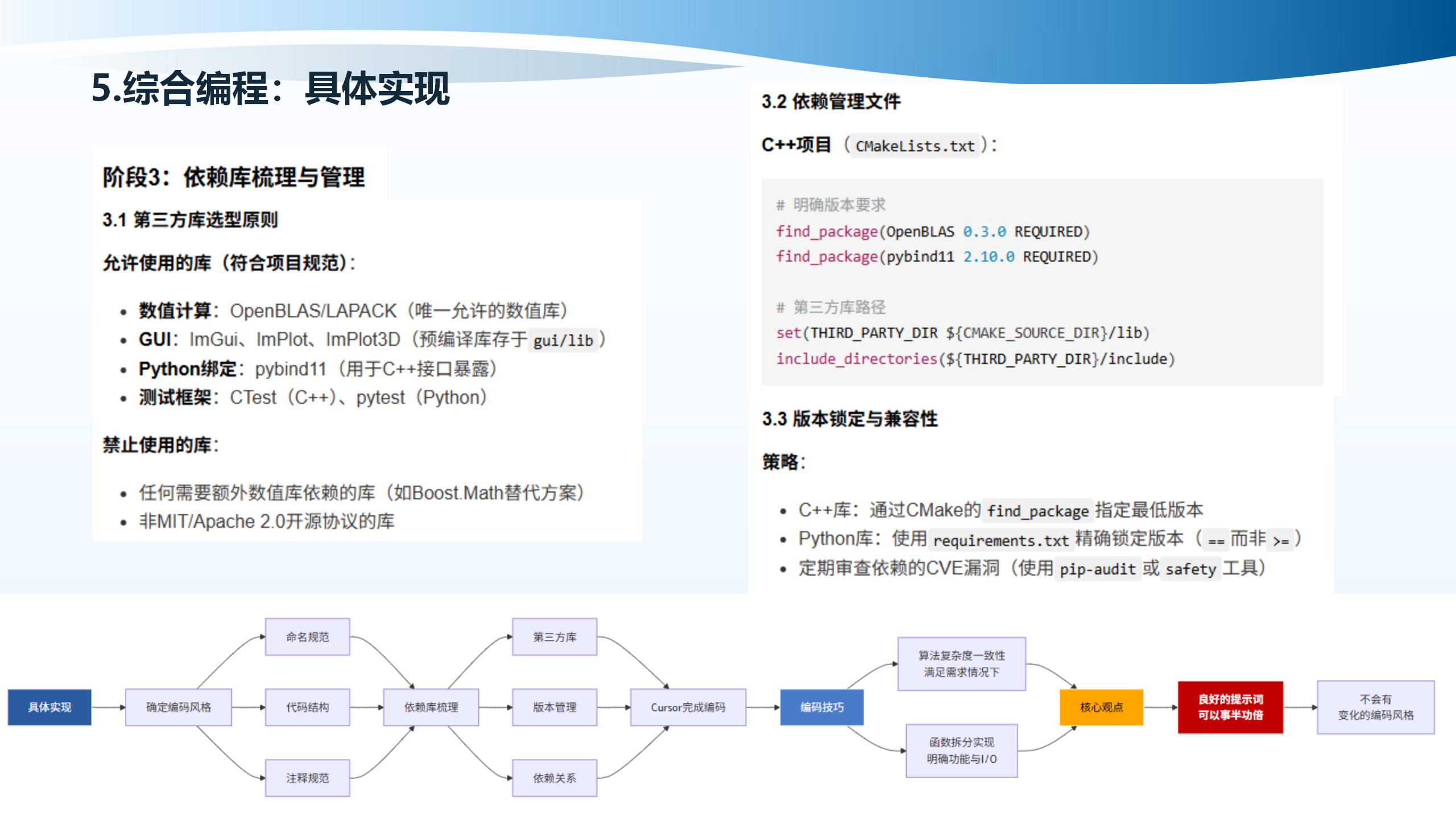
5.9 具体实现:基于Cursor的智能编码实践
阶段4是基于Cursor的智能编码实践。提示词工程的三层架构包括:系统提示词层(设定AI角色,如专业C++/Python工程师;定义全局约束,如仅使用OpenBLAS;命名规范、项目级编码规范、目录结构约定,存储于.cursorrules,src/include/等),工程提示词层(具体函数实现指令、Bug修复/重构指令、保持接口不变),任务提示词模板(功能描述、输入/输出规范、约束条件、测试用例)。
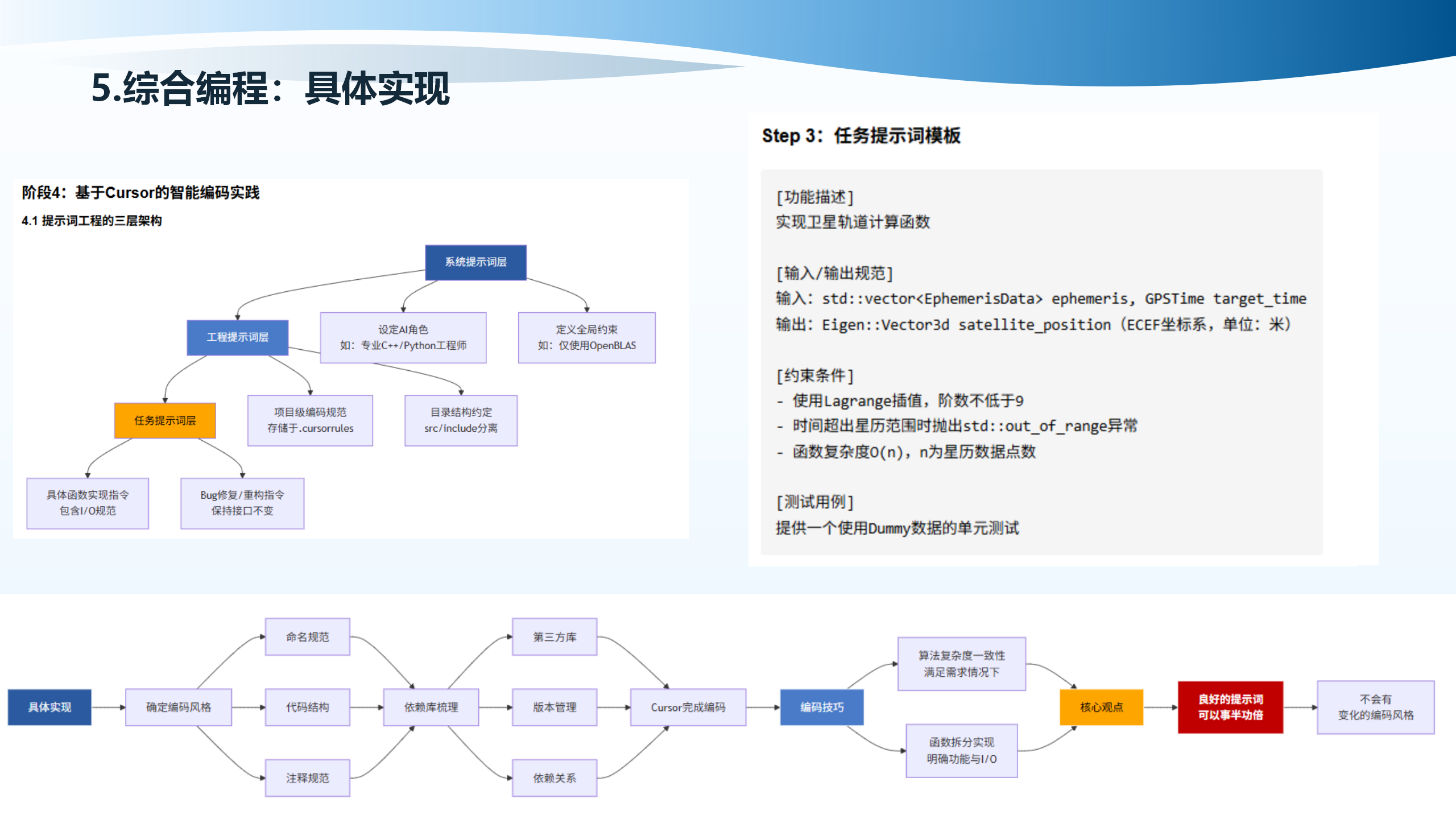
5.10 软件测试
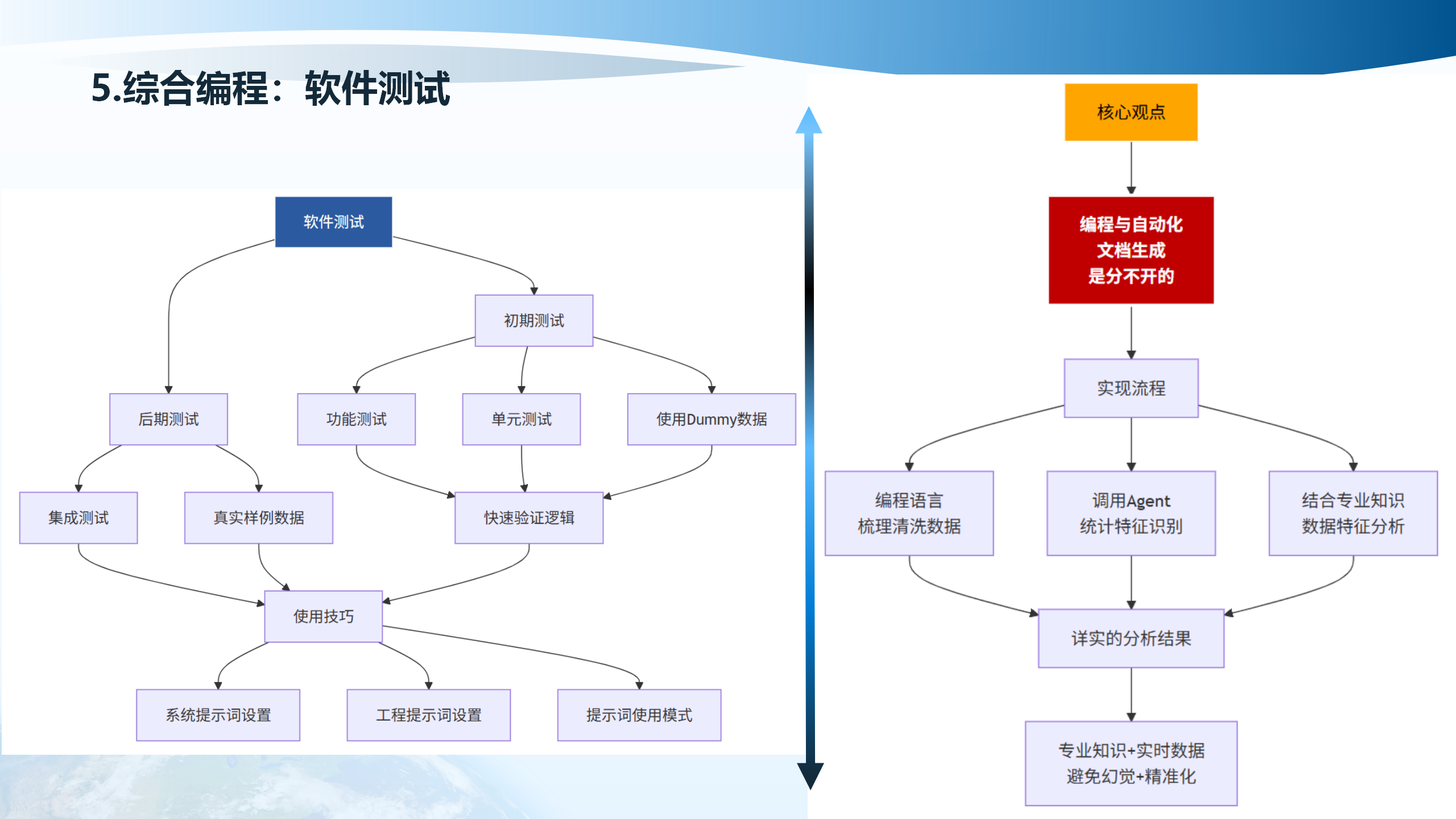
软件测试包括初期测试和后期测试。初期测试包括功能测试、单元测试,使用Dummy数据快速验证逻辑。后期测试包括集成测试,使用真实样例数据。系统提示词设置、工程提示词设置、提示词使用模式是编程与自动化分不开的关键。
编程语言、调用Agent、结合专业知识,梳理清洗数据、统计特征识别、数据特征分析,详实的分析结果。专业知识+实时数据,避免幻觉+精准化。
5.11 技巧与习惯
技巧与习惯包括:勤于在GitHub追踪、了解本行业及相关领域(如高性能计算、可视化)的开源程序现状,多发现相关Github项目并结合DeepWiki进行深度学习了解数学物理原理、软件架构、数据流以及编程技巧。
勤于在GitHub、Zenodo、code.google等搜索与收集本专业相关的数据集及数据接口、相关项目,能够快速定位相关的代码功能,同时勤于了解大语言模型现状,收集与自己职业相关的MCP或者Agents等相关的技术。
勤于结合专业领域论文(如来自arXiv)通过大语言模型进行研究前言与现状追踪、进行行业方向判别,使用Cursor等工具系统性探索相关研究可落地性、以及未来具有的可拓展方向,并结合已有技术、数据以及能力去规划可实现性子任务。
尝试以小功能形式增量改写与升级自己的程序,并对相关工作进行梳理与流程化。从易到难,尝试基于大模型进行知识探索与学习,基于多种方式、多种维度学习某知识点或者某新技能;学会对项目与问题的剖根探索,如任务或者依赖库之间的关联进行深度分析与溯源。

六、进阶技术:开发通用/专业工具与工作流
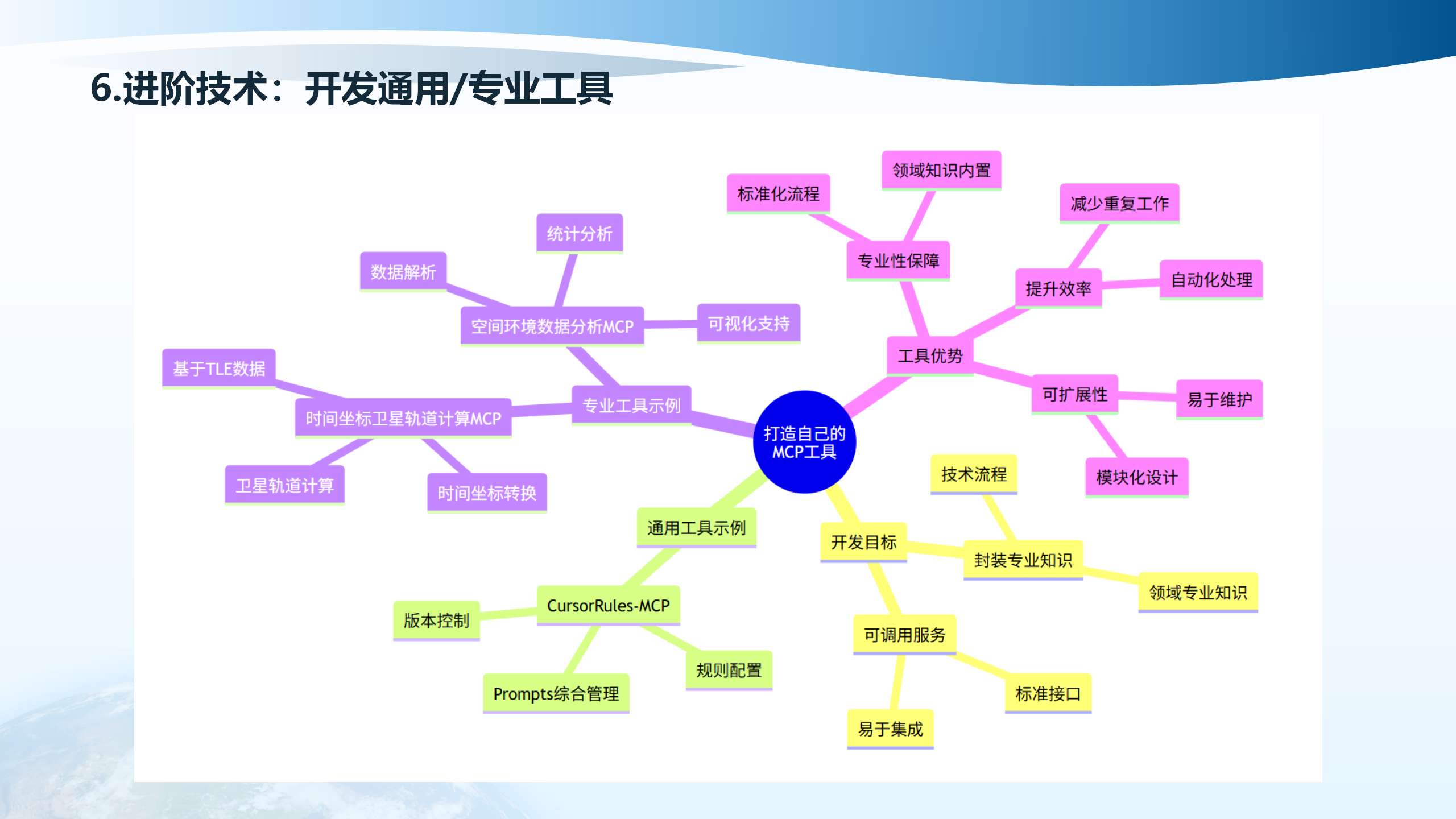
6.1 开发通用/专业工具
开发通用/专业工具包括空间环境数据分析MCP、卫星轨道计算、时间坐标转换等专业工具示例。
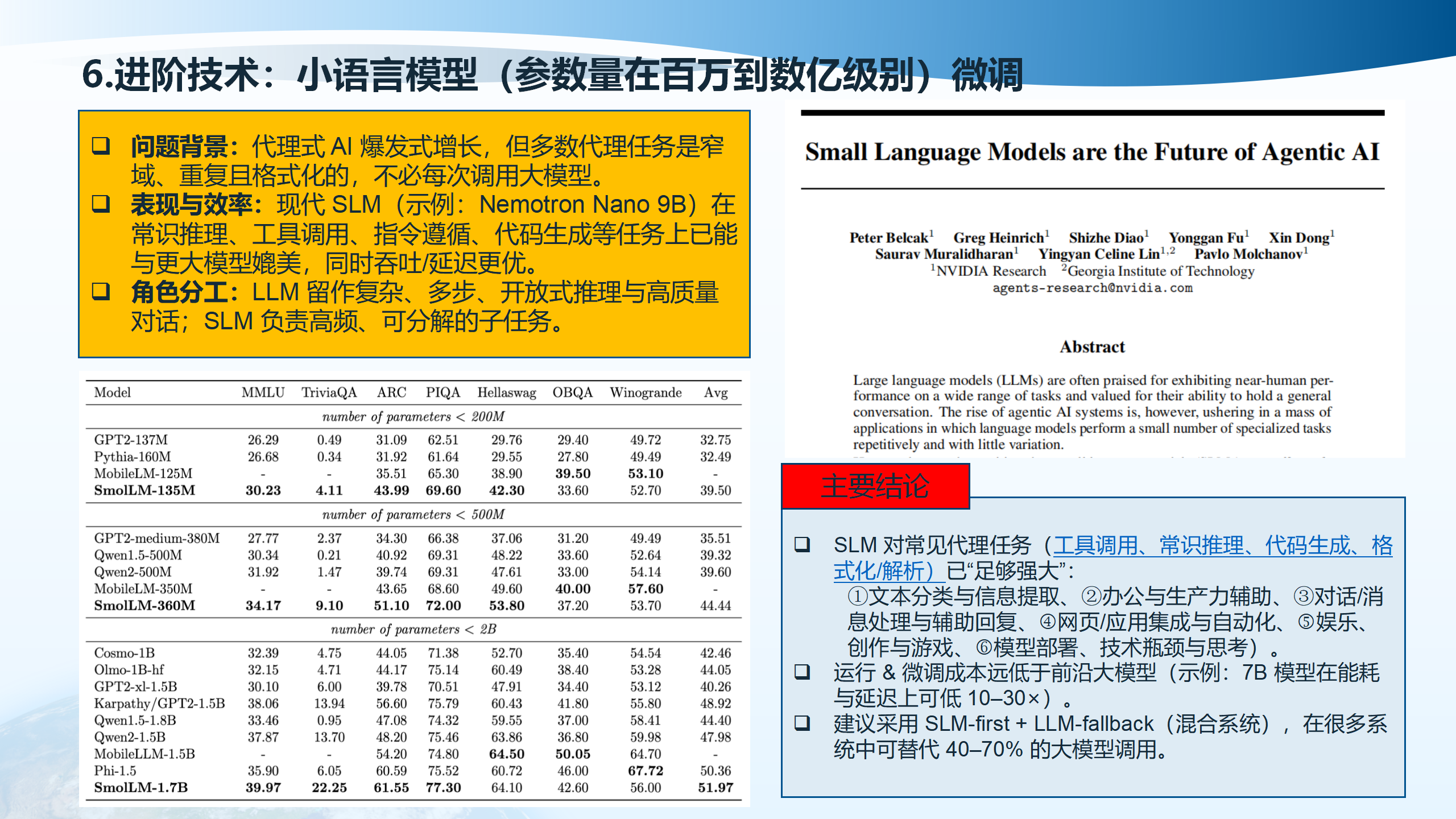
6.2 小语言模型(Small Language Model, SLM)
小语言模型(参数量在百万到数十亿之间)正在成为Agentic AI的未来。根据研究,SLM对常见代理任务(工具调用、常识推理、代码生成、格式化/解析)已”足够强大”,包括文本分类与信息提取、办公与生产力辅助、对话/消息处理与辅助回复、网页/应用集成与自动化、娱乐、创作与游戏、模型部署等场景。
运行与微调成本远低于前沿大模型(示例:7B模型在能耗与延迟上可低10-30倍)。建议采用SLM-first + LLM-fallback(混合系统),在很多系统中可替代40-70%的大模型调用。
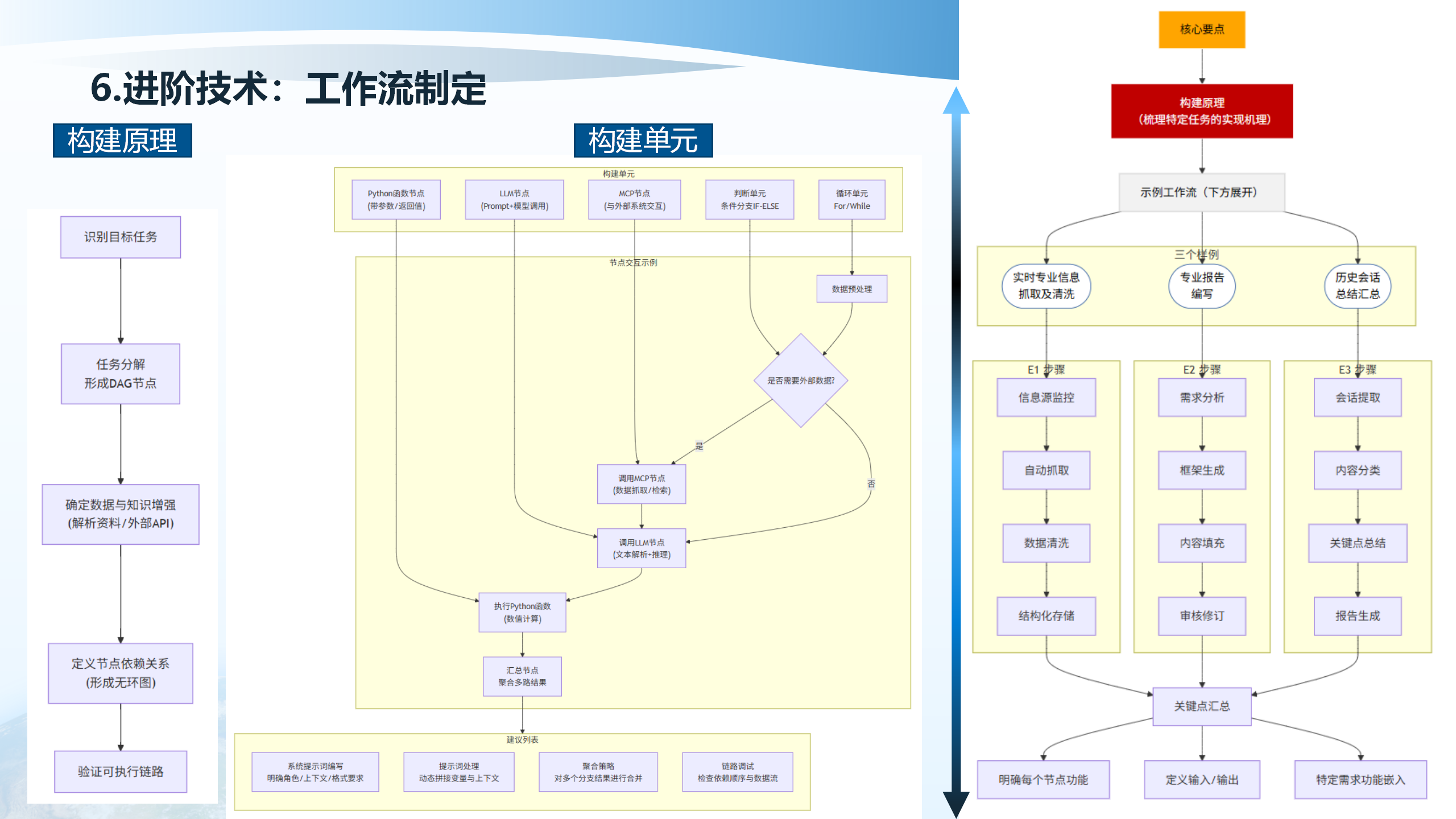
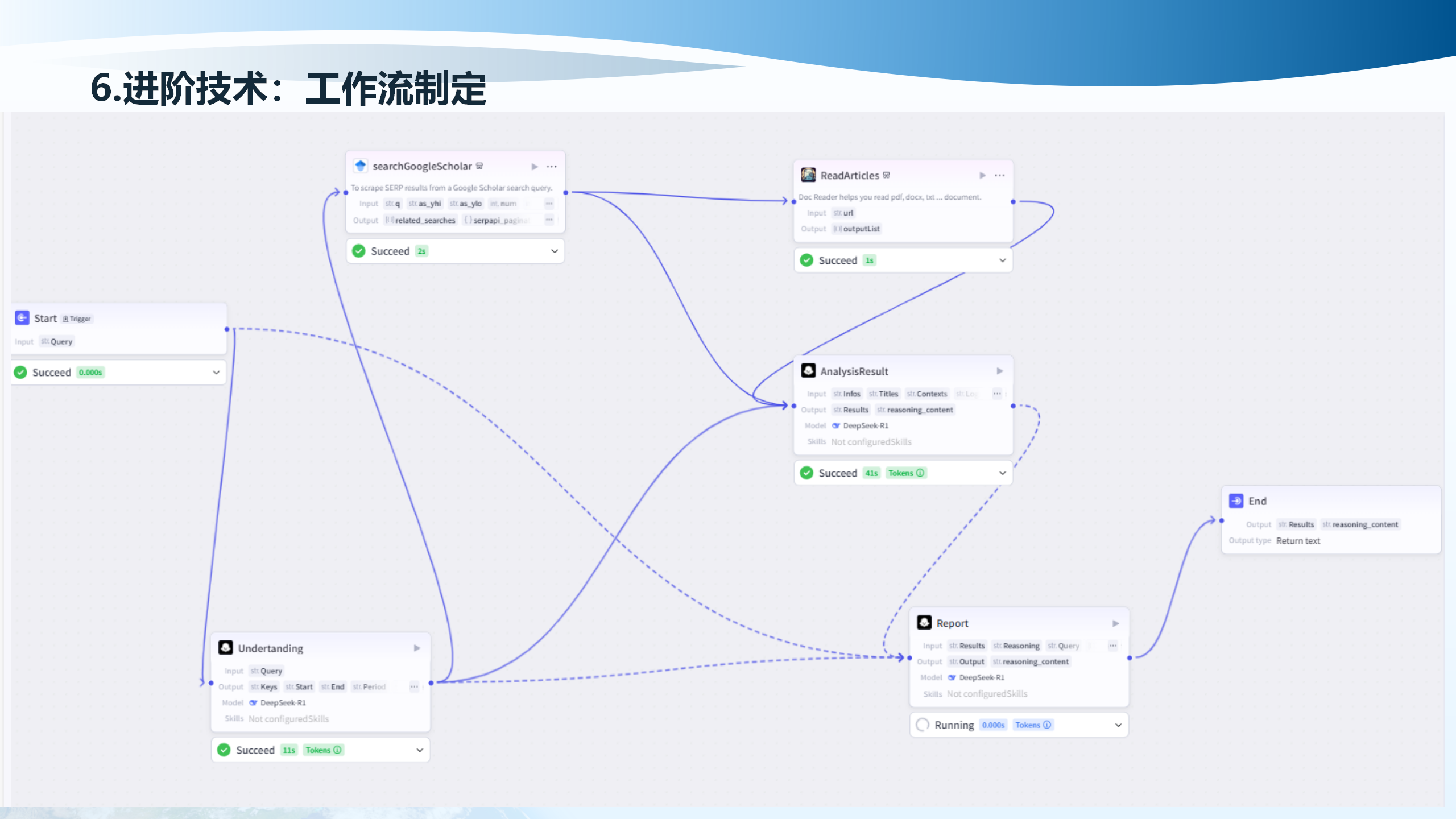
6.3 工作流制定
工作流制定的构建原理包括:构建单元(Python函数节点、LLM节点、MCP节点、判断单元、循环单元)、节点交互示例(数据预处理、任务分解、形成DAG节点、是否需要外部数据、调用MCP节点、确定数据与知识增强、调用LLM节点、执行Python函数、定义节点依赖关系、汇总节点)。
系统提示词编写、提示词处理、RAG、链路调试、验证可执行链路、明确角色/上下文/格式要求、动态拼接变量与上下文、对多个分支结果进行合并。
示例工作流包括:实时专业信息抓取及清洗、专业报告编写、历史会话总结汇总。信息源监控、自动抓取、数据清洗、结构化存储、关键点汇总、需求分析、框架生成、内容填充、审核修订。明确每个节点功能、定义输入/输出、特定需求功能谨入。
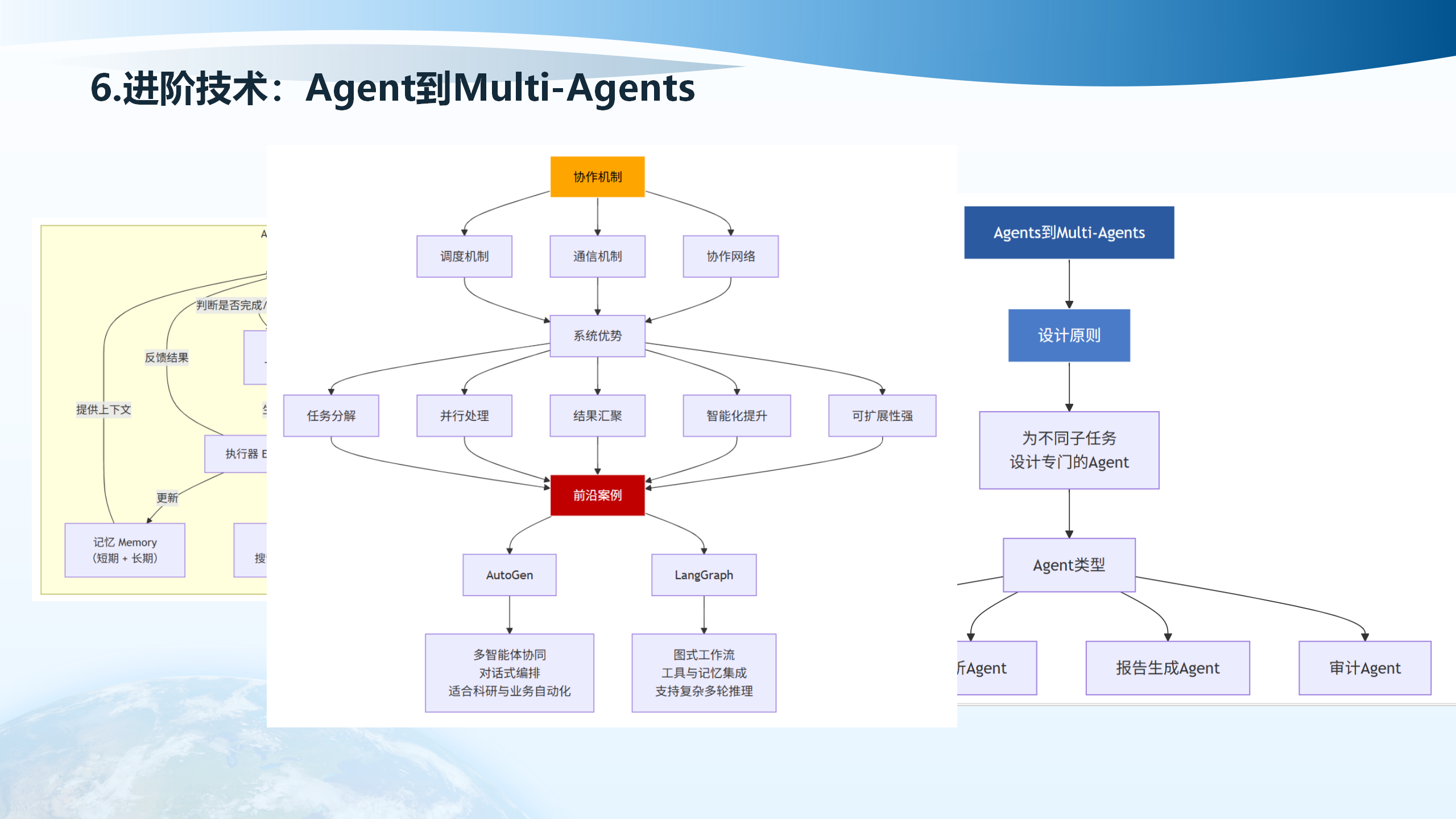
6.4 Agent到Multi-Agents
Agent到Multi-Agents的架构包括:用户交互层(Client、会话管理器Session Manager、对话历史、上下文窗口)、核心编排与状态管理(LangGraph Planner动态生成/修订工作流、调度与编排器Orchestrator、节点调度、错误处理/重试)、执行与能力层(MCP LARK注册/调用/鉴权、Agent: DataFetch、Agent: Action、Agent: Critic/Verifier、SUTRA Special Tools、数据库查询、计算服务)、外部系统/API(CRM、ERP)、记忆存储Memory Store(短期Redis/DB、长期VectorDB Pinecone/Milvus/FAISS)、消息总线Message Bus(Kafka/RabbitMQ)、监控与日志Monitoring(Prometheus/Grafana/LangSmith)。
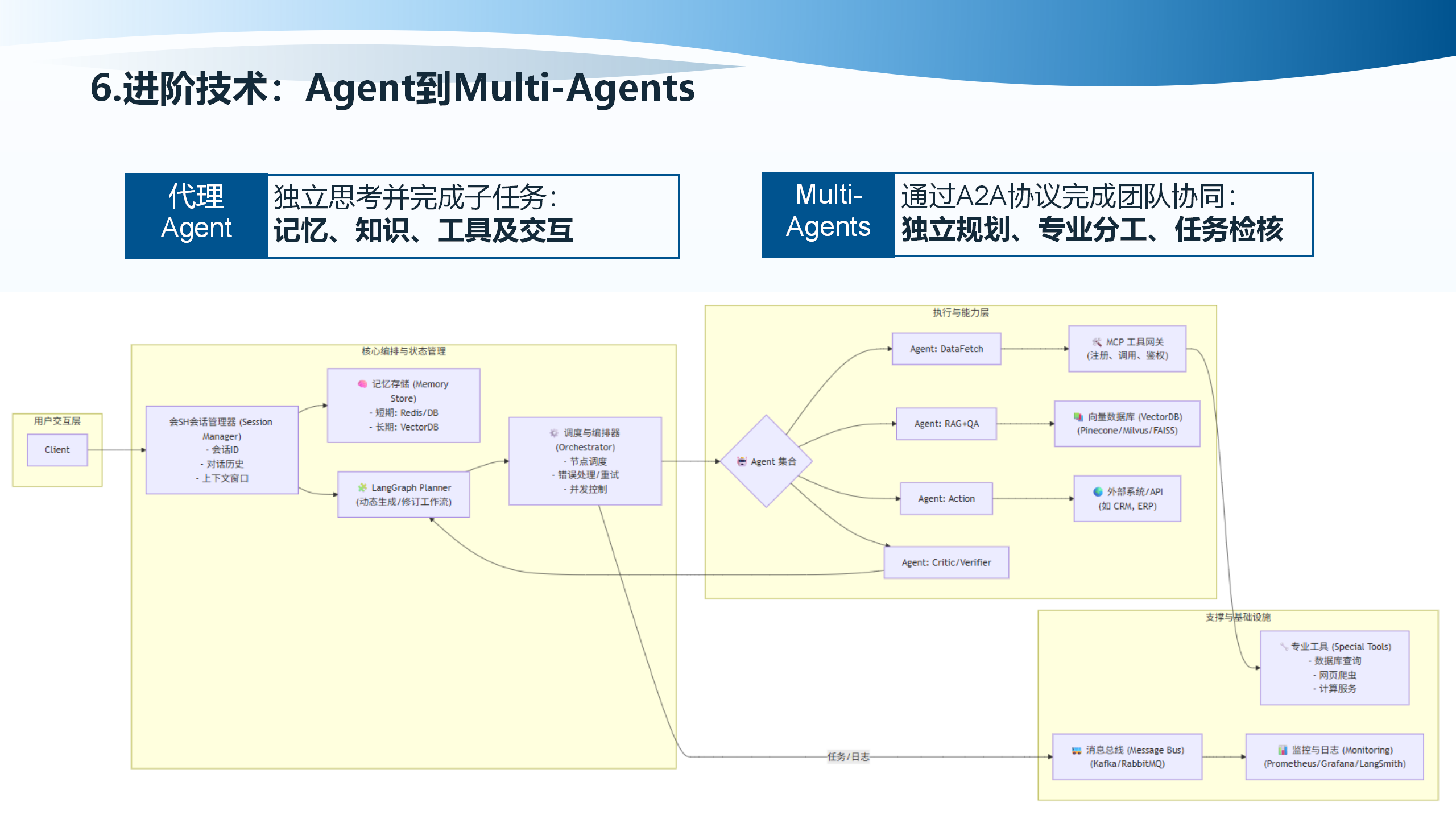
Multi-Agents的系统优势包括:任务分解(为不同子任务设计专门的Agent执行器)、并行处理、结果汇聚、智能化提升、可扩展性强。前沿案例包括:AutoGen(多智能体协同、对话式编排)、LangGraph(图式工作流、工具与记忆集成)、报告生成Agent、审计Agent等。适合科研与业务自动化,支持复杂多轮推理。
七、资源整合:大语言模型、MCP、工作流及Agent框架
7.1 大语言模型
大语言模型常见架构包括:编码器(如BERT)侧重理解与表示,解码器(如GPT)用于自回归生成,编码器-解码器(如T5)适合序列到序列任务。另有RAG结合外部知识提高准确性,专家混合(MoE)通过稀疏路由兼顾效率与容量。实际使用常配合蒸馏、量化与并行推理等优化以降延迟和内存占用。不同架构在训练目标、推理成本与应用场景上各有优势,应按任务选择。
大语言模型常见微调有:全量微调(更新全部参数,适用于BERT/GPT任务化训练)、参数高效微调(PEFT),例如Adapter、LoRA(低秩注入)、prefix/prompt-tuning(可训练前缀或提示)、指令微调用于对话与指令遵循、RLHF用人类反馈优化生成质量。各法在性能、成本、适用场景上各有特点,常与蒸馏、量化结合使用。
大语言模型常见量化包括:权重量化,将32位浮点压缩为8位(如INT8量化)以降低显存和计算成本;激活量化(如SmoothQuant)同时压缩中间激活值以减少推理延迟;混合精度量化(FP16/BF16+INT8)在保持精度的同时提升速度;极低比特量化(如QLoRA使用4位)进一步节省显存并支持大模型在单卡上微调与推理。不同量化策略在精度保持与资源节约间权衡,常与剪枝、蒸馏结合以兼顾模型性能。
大语言模型常见的剪枝方法包括结构化剪枝(如按权重重要性删除整个注意力头或前馈层通道)和非结构化剪枝(如移除稀疏权重),以减少参数量和推理开销。蒸馏则通过大模型教师指导小模型学生学习输出分布,例如DistilBERT保留BERT性能同时参数减半,TinyLlama在保持生成质量的前提下降低显存需求。剪枝和蒸馏常结合量化与参数高效微调,在保持精度的同时实现轻量化部署,适用于边缘设备及低延迟应用。

7.2 MCP、工作流及Agent框架
MCP类型(Inputs)包括:把Tool MCP映射为”可注册节点/插件”,例如将Tool MCP的能力声明自动转成n8n节点或Dify插件。Policy MCP做前置审查:在工作流入口或Agent调用前,先用Policy MCP校验权限/脱敏。Context/Memory MCP映射到向量DB与Memory层:可在可视化构建器中把检索节点通用化,或在LangChain/Graph中实现统一Memory API。
工作流引擎要可靠编排+企业整合(调度/日志/重试/合规):Dify/Coze/n8n/企业Workflow平台(把LLM作为节点)。企业级工作流/编排平台(带LLM集成):n8n。LM-first/Agent-first平台(低代码/产品化):Dify,Coze。可视化/节点式LLM流程构建器(偏”看得见的链路”):Flowise/Langflow/Botpress(可视化流)。开发者向的编程/控制层(框架级,灵活可编程):LangChain/LangGraph;AutoGen/AgentGPT/SmolAgents等开源Agent框架。

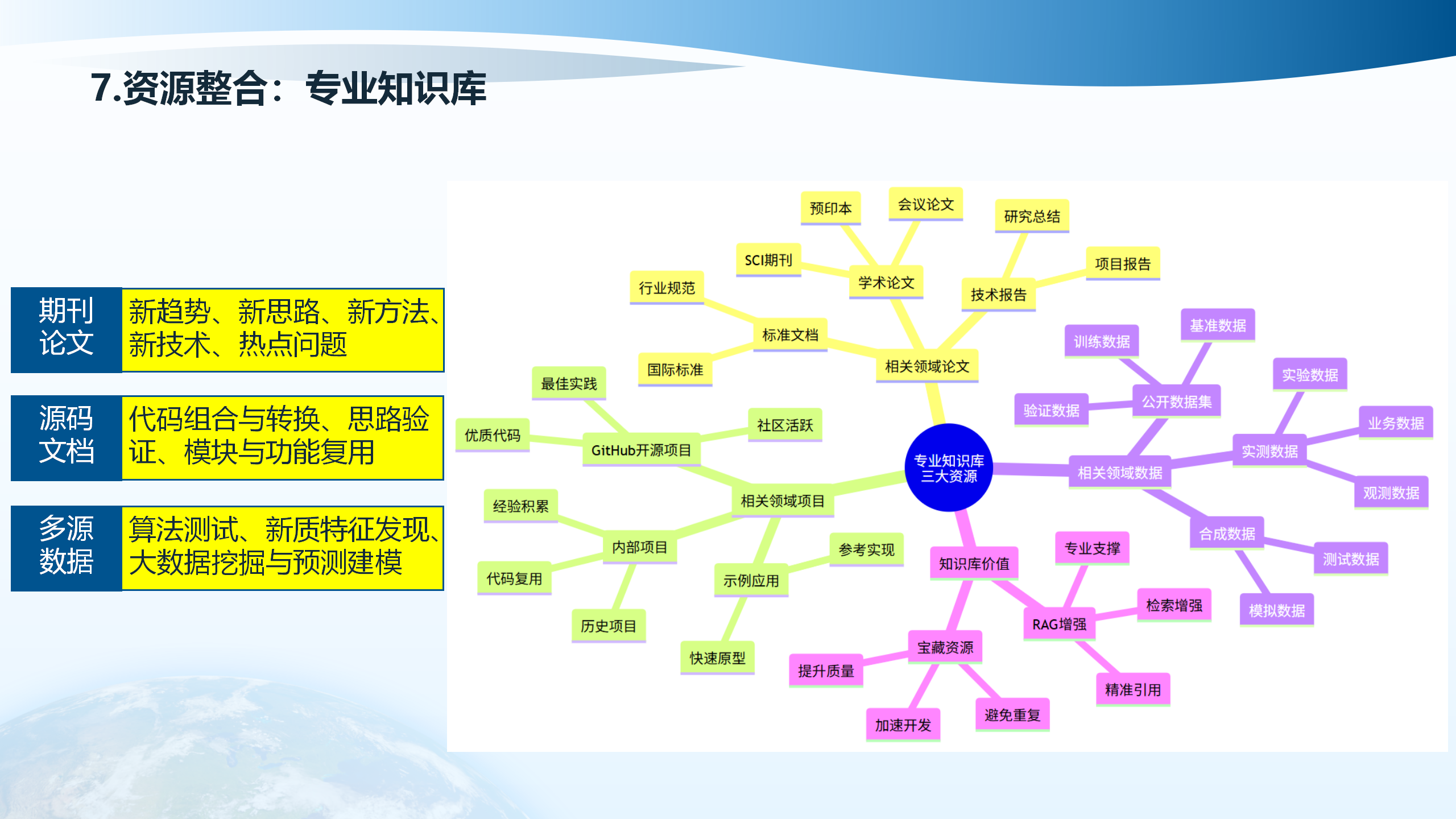
7.3 专业知识库
专业知识库是AI工程应用的重要支撑,通过构建领域知识库,可以为RAG系统提供准确的专业信息,提升AI应用的专业性和可靠性。
八、未来趋势:AI技术发展的方向与影响
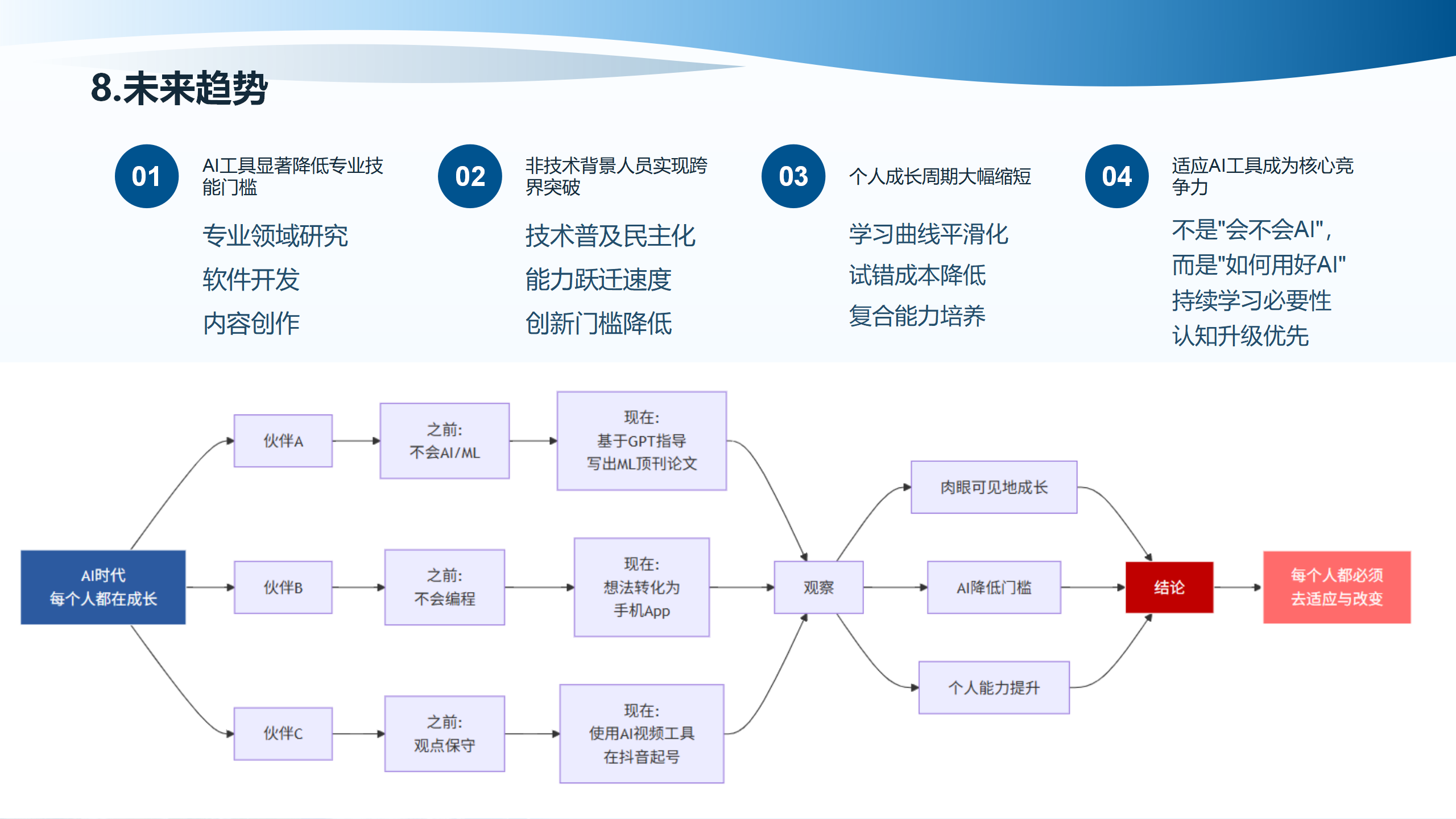
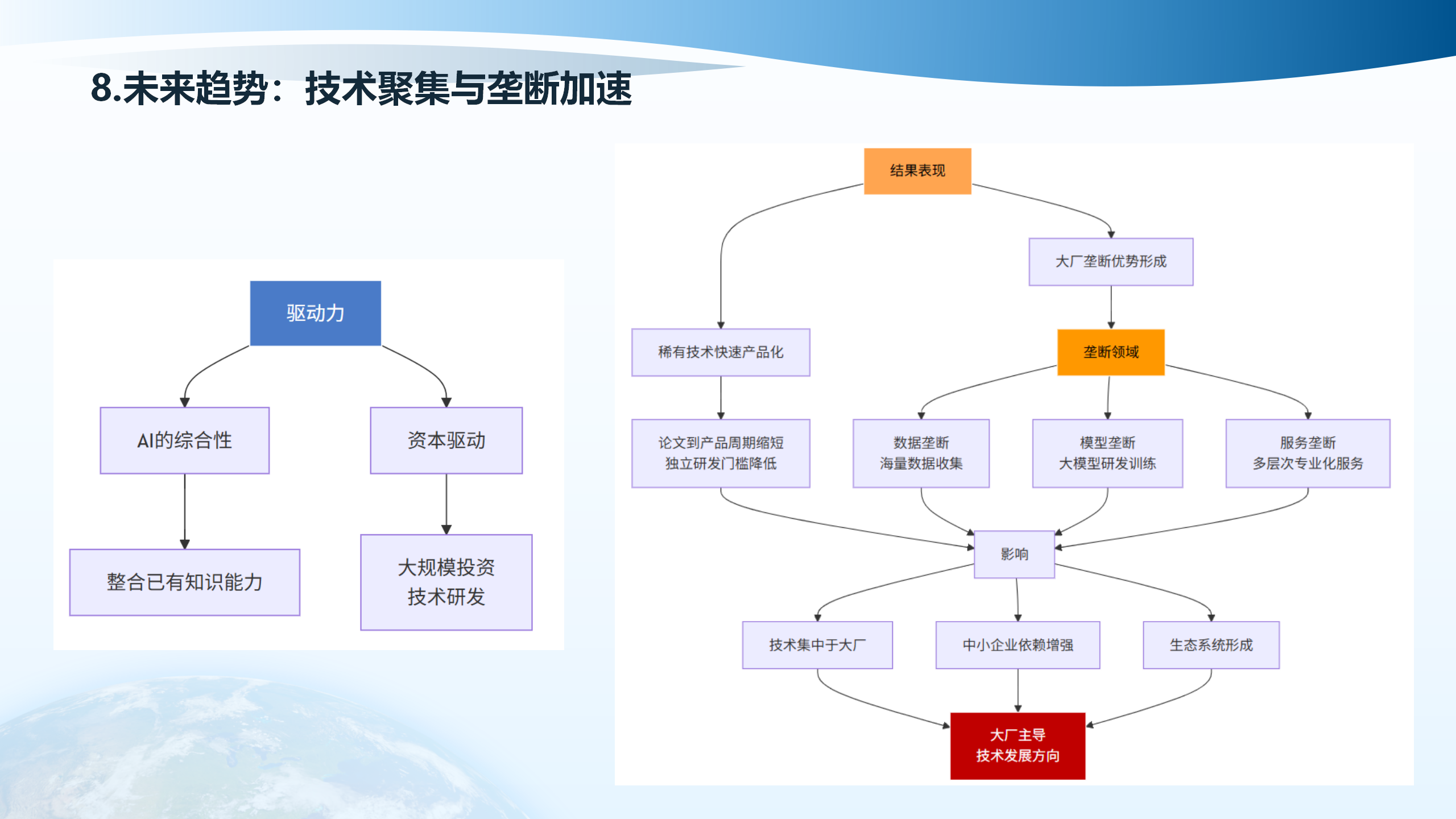
8.1 个人成长周期大幅缩短
AI技术的普及使得专业领域研究、软件开发、内容创作等领域的个人成长周期大幅缩短。技术普及民主化、学习曲线平滑化、创新门槛降低、复合能力培养、认知升级优先。之前需要多年积累的专业技能,现在可以通过AI辅助快速掌握。每个人都必须去适应与改变,个人能力提升、多领域技术融合加速。
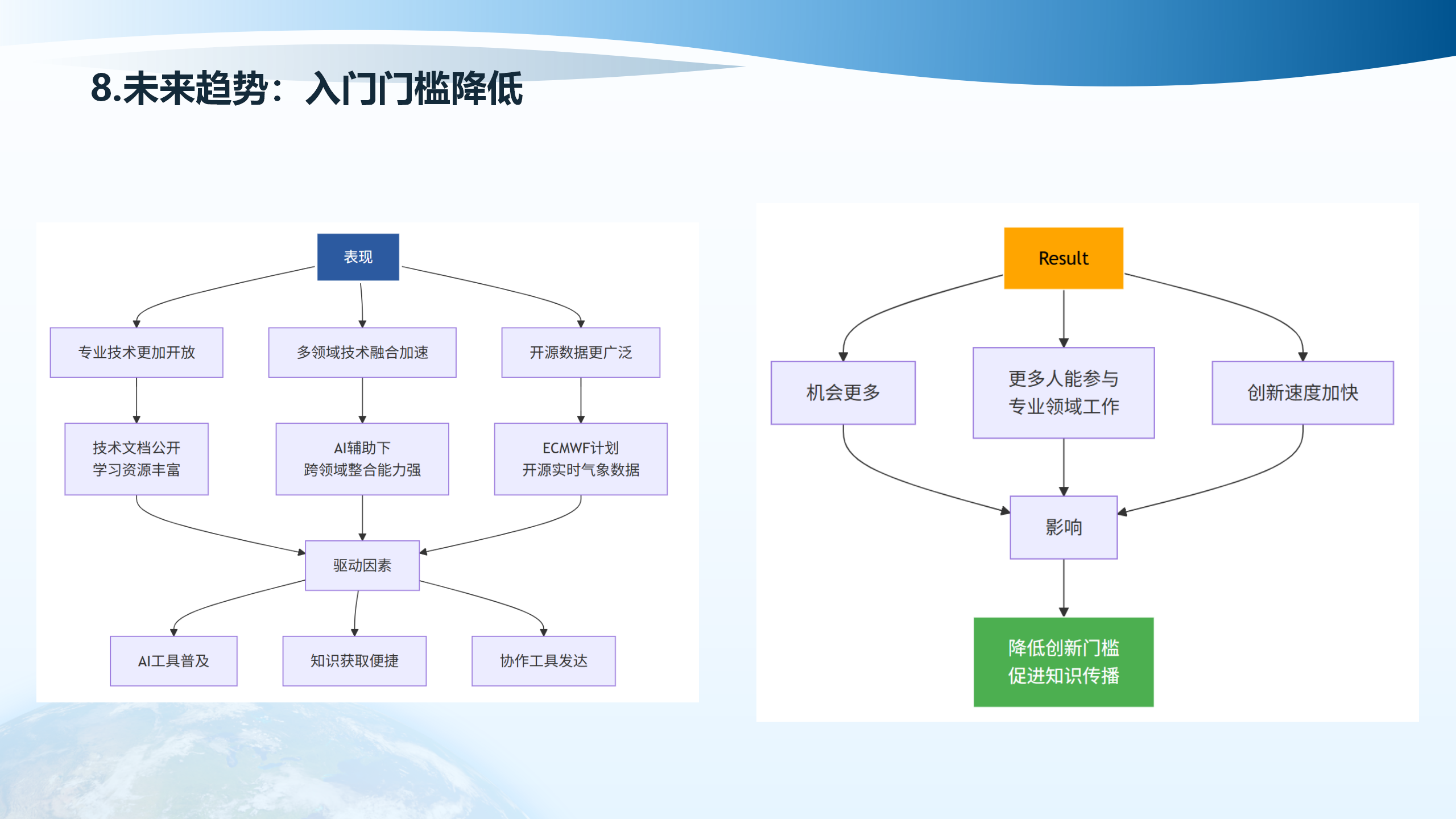
8.2 专业技术更加开放
专业技术更加开放,多领域技术融合加速,开源数据更广泛。技术文档公开,学习资源丰富。AI辅助下跨领域整合能力强。ECMWF计划开源实时气象数据。驱动因素包括:AI工具普及、知识获取便捷、协作工具发达,更多人能参与专业领域工作,促进知识传播,创新速度加快。
8.3 技术发展方向
稀有技术快速产品化,AI的综合性影响包括:论文到产品周期缩短、独立研发门槛降低、海量数据收集、大模型研发训练、多层次专业化服务。大规模投资、技术研发、技术集中于大厂、中小企业依赖增强、生态系统形成。
九、总结
理解AI现状与核心概念,掌握Cursor等工具的实战方法。AI历史演进、基础到高级概念、能做什么不能做什么、工程角色定位、应用优势分析、需求落地方法,明确AI能力边界与工程应用。
综合撰稿流程、综合编程实践、MCP工具配置、进阶技术路线、资源整合策略,为工程技术人员提供从理论到实践的完整指南。


来源:《AI在工程应用中的实践》